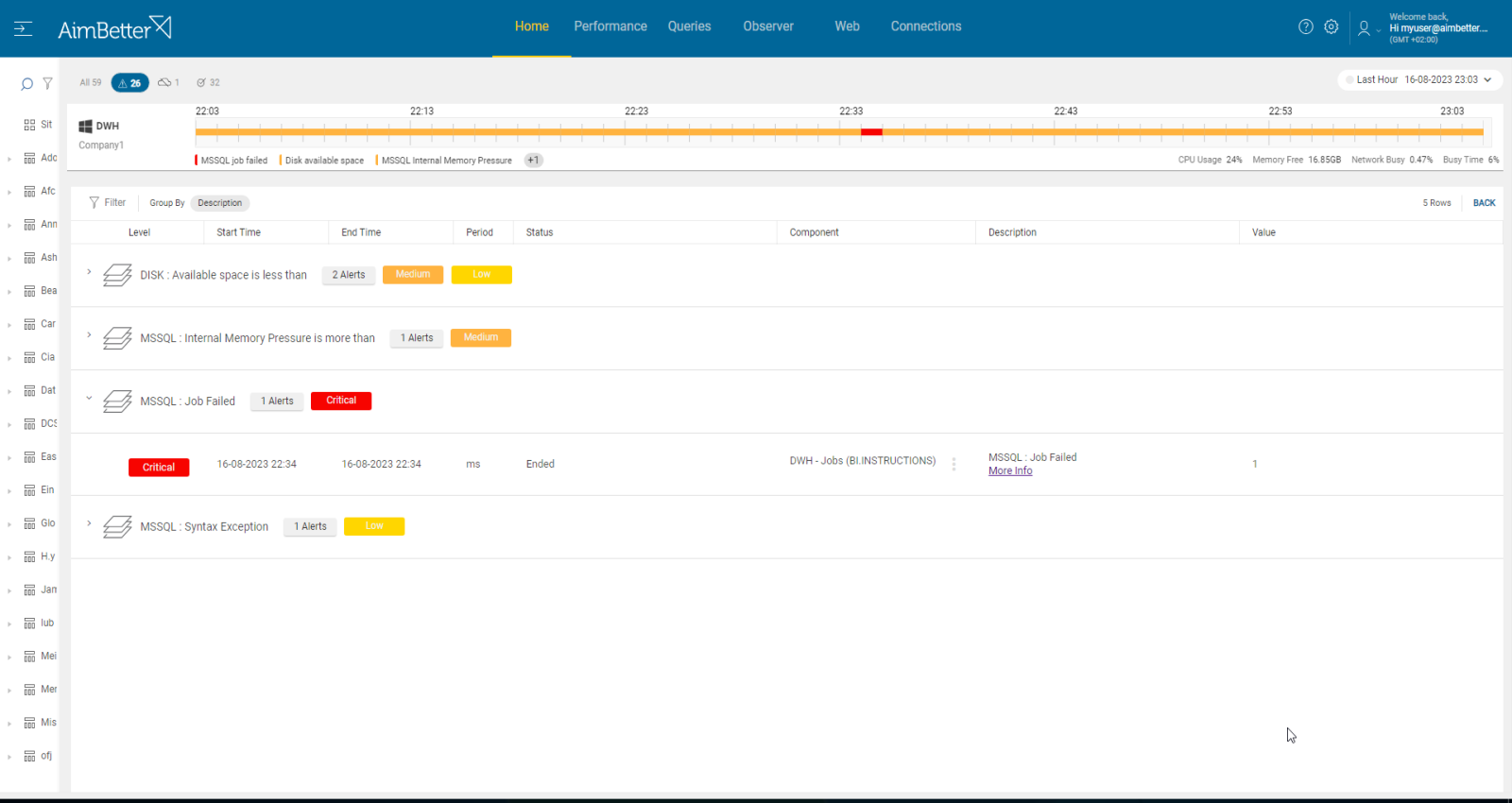
Scheduled jobs in a database system (such as SQL Server Agent jobs or Oracle DBMS_SCHEDULER jobs) are used to automate tasks like backups, log archiving, or data transformations.
When a job fails to complete successfully, it’s marked as “Failed” (SQL Server) or logged with an error (Oracle), potentially disrupting application performance or causing data integrity risks.
Find out how you can save hours of work when investigating the root cause of this issue.
Symptoms :
SQL job failed.
Impact: High
This alert indicates that one or more steps in the designated SQL job were not completed successfully. This may cause data loss, disrupt the application’s integrity, or reduce performance.
Expected behavior :
SQL jobs should not fail. They should run successfully without reducing performance or harming the application’s activity.
Possible causes:
1- Timeout – SQL busy. Priority: Medium
When a job’s execution takes longer to complete than an expected time frame, based on current settings, it will fail due to a time out.
Timeouts are widely used in many applications and environments to ensure that tasks don’t stay active for too long, reducing the chances of harming performance.
There are many causes for time-outs, the first being long-running queries. Additional causes, like resources, network issues, deadlocks, and more, will be discussed further.
Problem identification:
Once you identify a timeout, try to check if it’s related to a job’s failure due to long-running queries and overload on performance metrics.
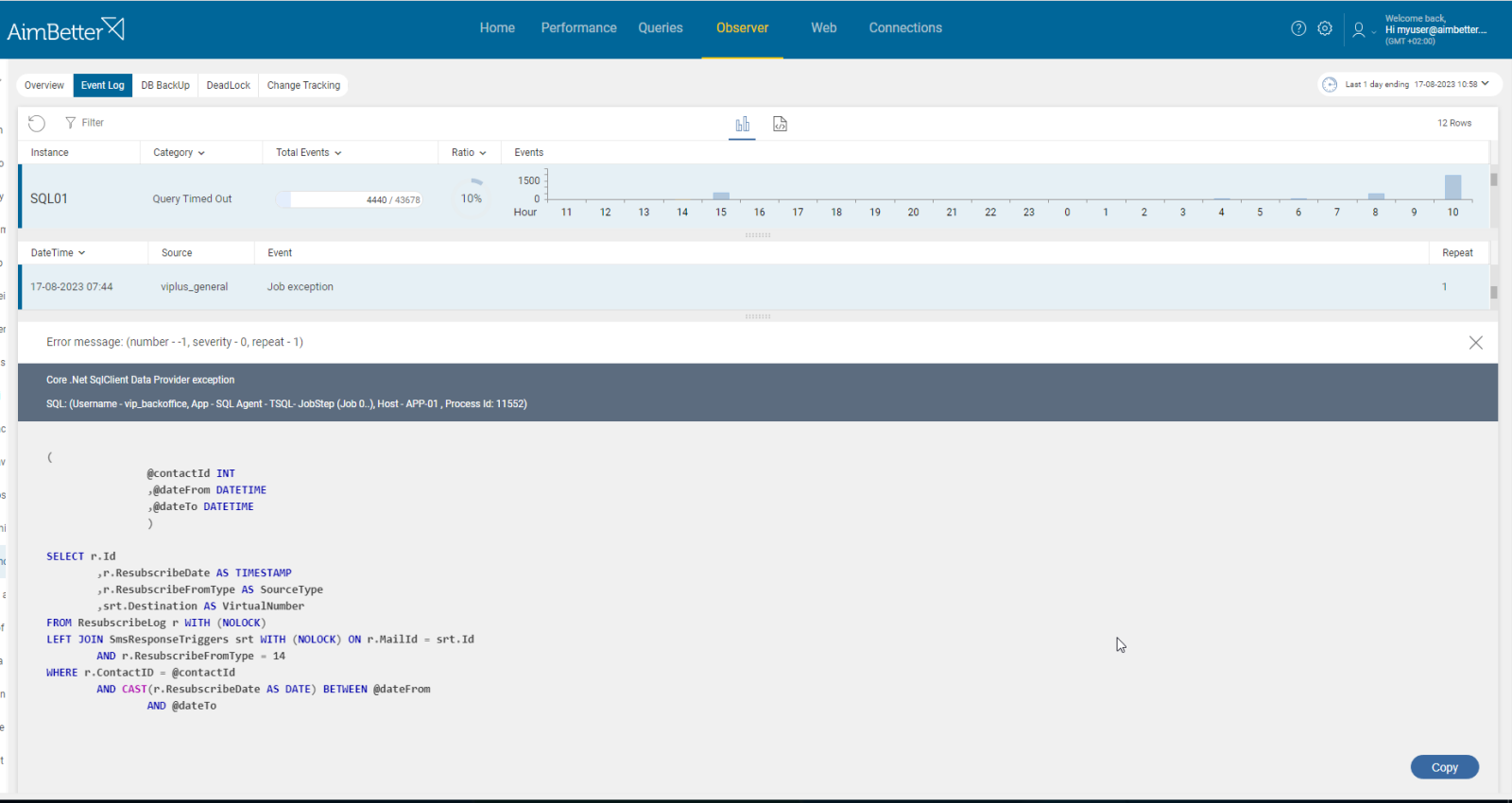
- Use tracking tools in order to identify long-running queries facing a time-out, identified as a job in application details. For SQL Server, you can use SQL Server Profiler. For Oracle, use Oracle Enterprise Manager. For Azure or AWS, use the Query Performance Insight tool. Take into account that tracking has started only when you activate it. Therefore, you don’t have historical events to compare with.
- Other possible options: For SQL Server, you can set extended events to follow over time-out events. Another option is to use DMVs (Dynamic Management Views) to collect more details about queries. For Oracle and Azure, you can use system views as well.
- Review logs, if possible, in order to collect more data.
- Compare these events with the error message of the job’s failure reason. In SQL Server, it is provided in the SQL Server Agent.
- Analyze the queries and find out how to prevent time out from happening again.
Recommended action :
Track the job event to locate the step that failed. Optimize query performance. Monitor the level of available memory, disk free space, and pagefiles life to provide the necessary resources. If possible, schedule the job to run in an appropriate time slot.
Check for outdated statistics, which can cause query performance issues within the job steps, leading to failures. Also, this information will be provided in the AimBetter monitor.
2- Code error. Priority: Medium
Syntax errors (e.g., PL/SQL or T-SQL syntax) or logical issues in job steps can cause failures. Syntax exceptions occur when the SQL language code is incorrect. Logical errors relate to incorrect query outputs.
Problem identification:
Check for the job’s failure error message and track it to recognize code exceptions.
- Use tracking tools in order to identify exceptions identified as a job in application details. For SQL Server, you can use SQL Server Profiler. For Oracle, use Oracle Enterprise Manager. For Azure or AWS, use the Query Performance Insight tool. Take into account that tracking has started only when you activate it. Therefore, you don’t have historical events to compare with.
- Other possible options: For SQL Server, you can set extended events to follow over SQL exceptions related to syntax. Another option is to use DMVs (Dynamic Management Views) to collect more details about queries. For Oracle and Azure, you can use system views as well.
- Review logs, if possible, in order to collect more data.
- Track this issue and check what can be fixed in the problematic queries.
Recommended action :
According to the reason for the syntax error, optimize the query in order to prevent the failure from happening again. Make sure to do tests in order to check if the job faces new errors when executing.
Make sure to actively follow logs or monitor this issue in order to debug it. You should identify and resolve code errors before they lead to job failures in production servers.
3- Inefficient query design or missing indexes. Priority: Low
Incorrect query code may result in inefficient data access, long duration of execution time, and bottlenecks to resources. Missing indexes mainly cause queries to run slower than best-practice options. In Oracle, you may also deal with bitmap vs. B-tree index choices. Besides this, Oracle has automatic indexing, which might impact analysis.
Query design might be inefficient for several reasons: full table scans, non-optimal use of joins, nested loops, and more. Missing indexes are related to non-optimal table scans and might cause blockings, resource overload, and slow query aggregation.
Both of these issues can be investigated using the execution plan.
Problem identification:
Once identifying job failure, check if the query’s execution has poor performance.
- Identify the job failure.
- Track the database server activity before, during, and after job failure: identify which SQL statements are consuming mostly the resources and have non-optimal execution plans. For SQL Server, you can use the built-in activity monitors or SQL Profiler. For Oracle, use Oracle Enterprise Manager. For Azure or AWS use the Query Performance Insight tool. This mission might be complicated and take hours or days of work, requiring a highly skilled DBA.
- Investigate the query code and execution plan, trying to look for missing indexes or excessive subqueries. In order to get this data, you have to run the query live again from the management studio, which might increase the overload and the investigation time of this issue. Make sure this query is not doing new inserts and updates before executing it. If so, change accordingly the code to do only SELECT statements.
- Examine index usage and fragmentation: Evaluate the usage and fragmentation of indexes in the database. Unused or fragmented indexes can impact query performance.
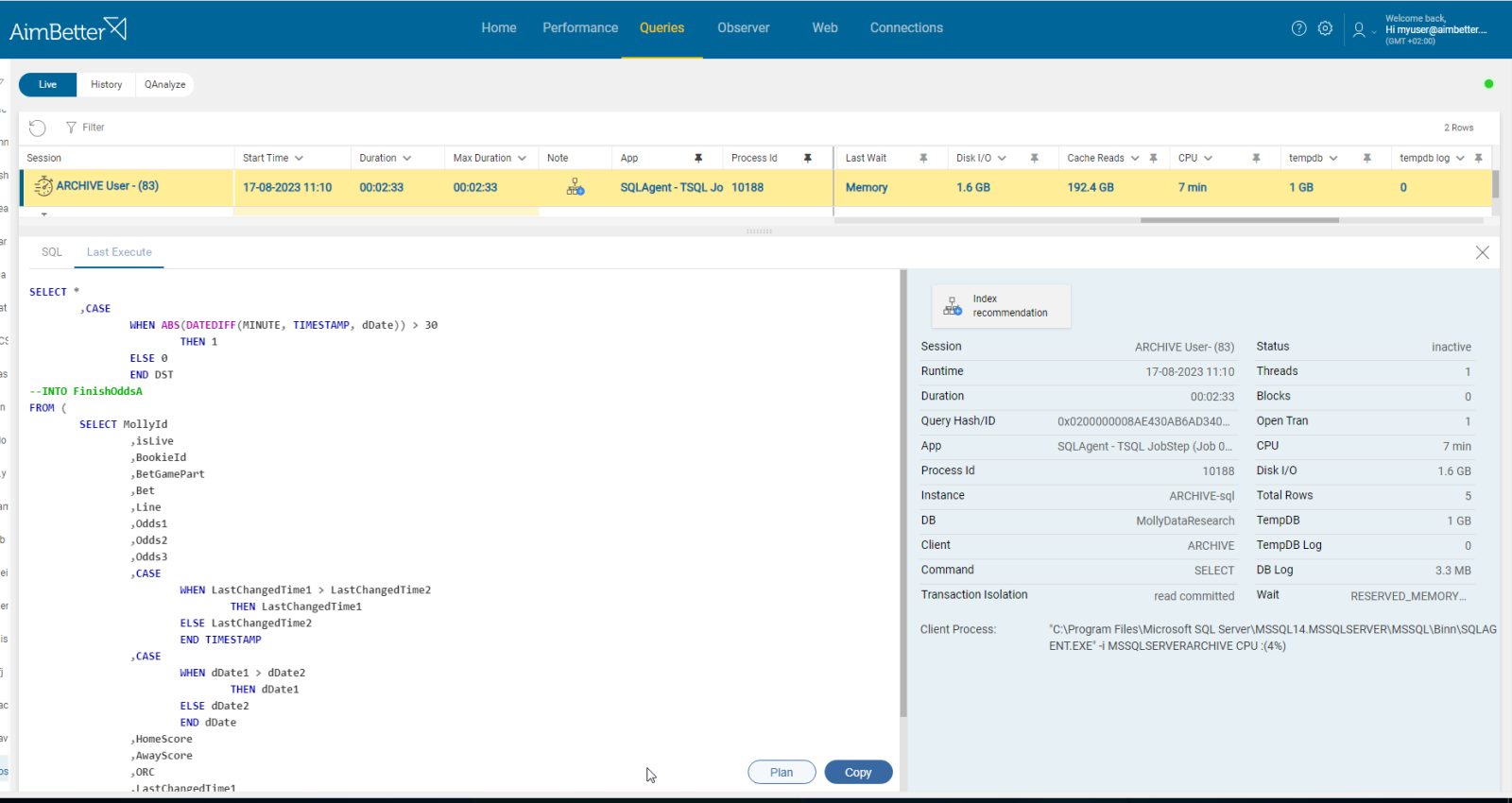
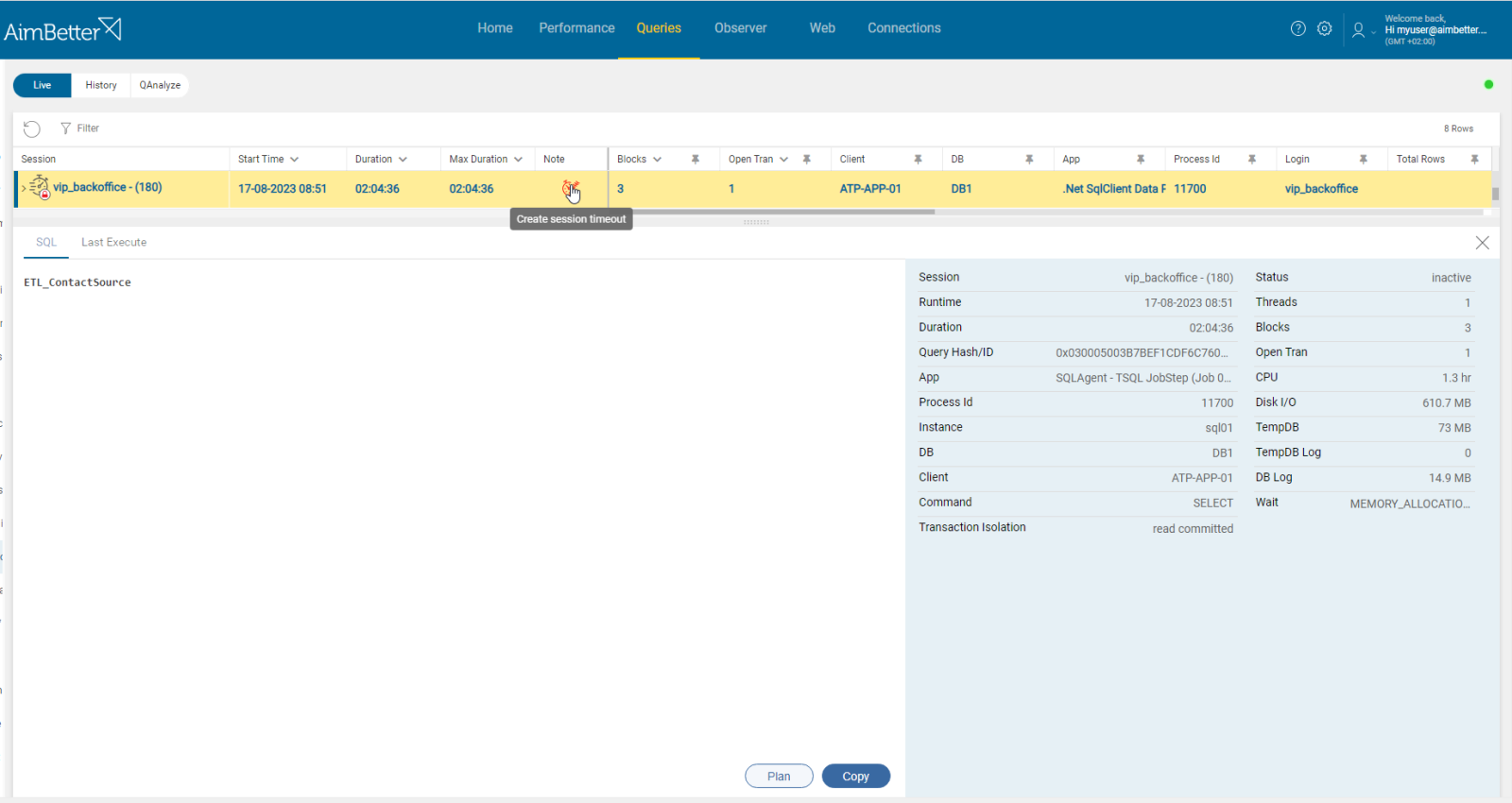
All running queries at the moment can be viewed from a single view with AimBetter.
You can filter and sort the queries by execution time or resource utilization and search for the application as a job.
Queries execution plan and missing indexes are available immediately, even while the query is running live! No need to waste time waiting or running it again. AimBetter also includes recommendation notes for the query’s improvement.
Recommended action :
Look for functions over fields that can be tuned or avoided in order to improve performance. Minimize the number of repeats (reading records more than once) as much as possible.
Break complex queries into more simple steps, and make sure to use proper filtering, WHERE clauses, and JOIN operations.
Make sure that each transaction has COMMIT (in case of no errors) and ROLLBACK (in any case of an error) statements where applicable.
Detect missing indexes by looking at the execution plans. Make sure you are using proper indexes. Add or delete indexes if possible and needed.
You should consult with a DBA who understands the data model before making these changes.
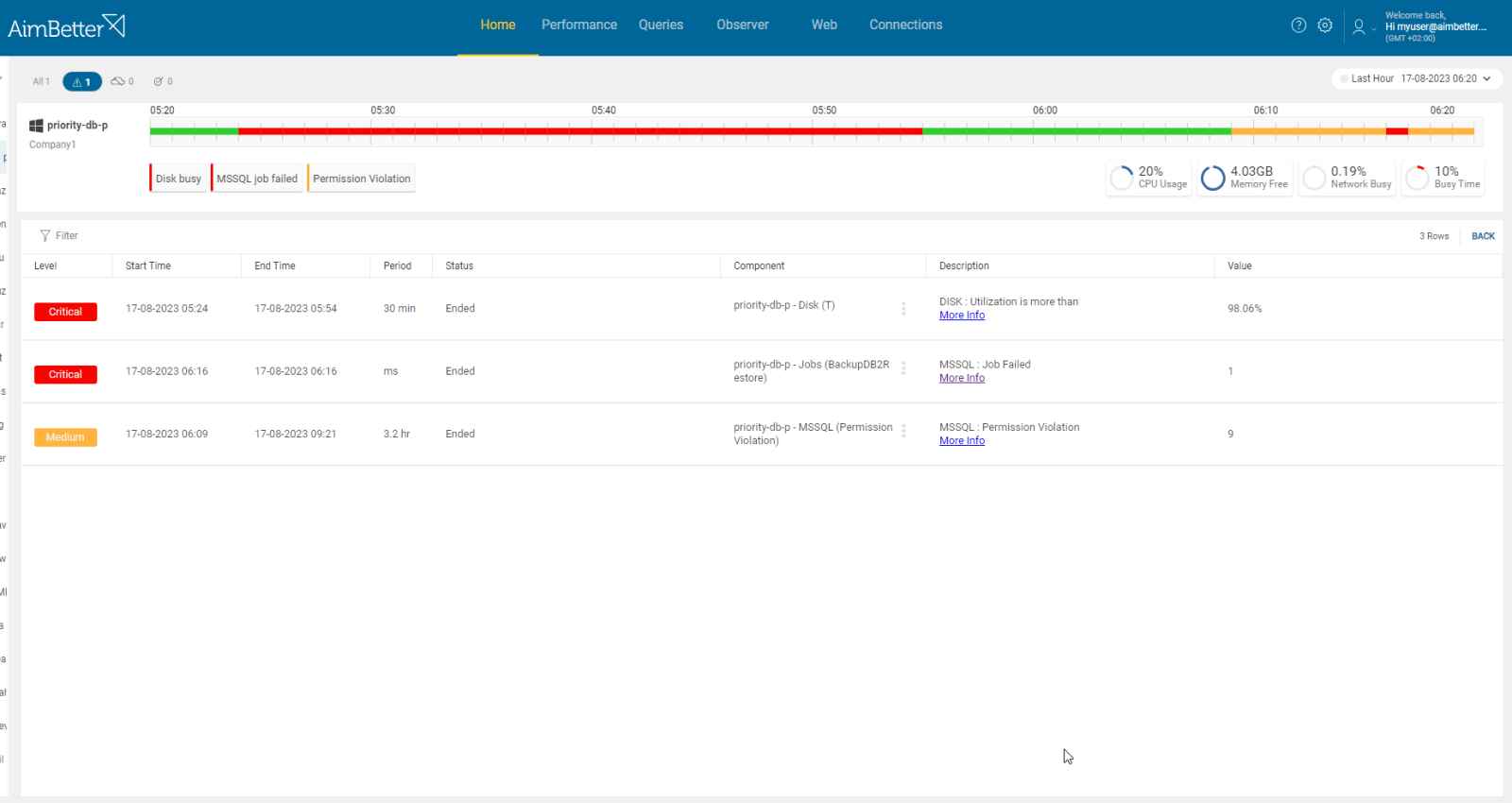
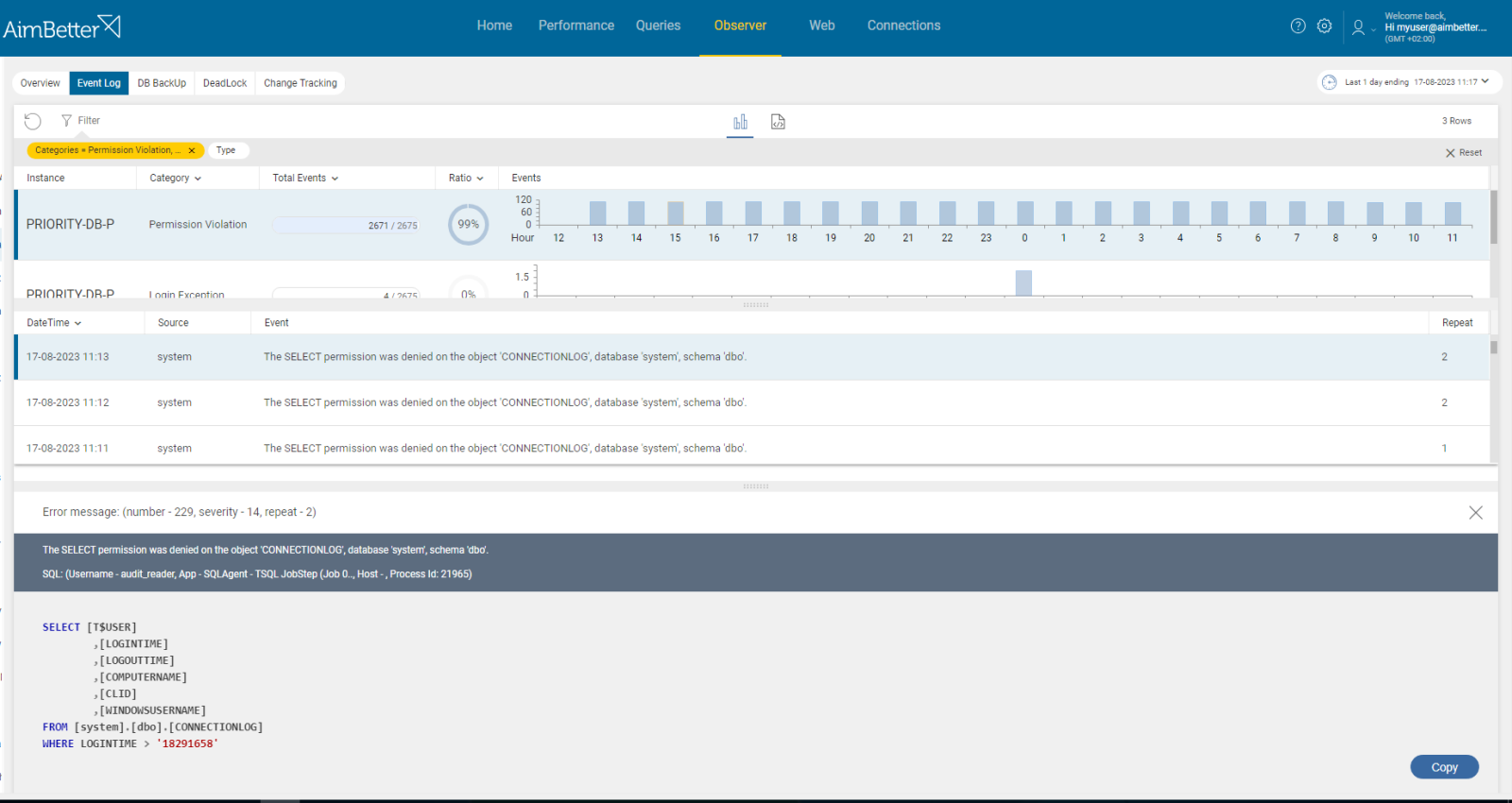
4- Permission Issues. Priority: Medium
A job might require permission to access database properties (tables, views, objects, schemas, and more), files, or other resources. In cases when these permissions are missing, the job will fail.
Oracle works with a roles and grants system, which is more granular and sometimes session-based.
Problem identification:
Job’s error message mentions that the jobs failed because of missing permissions.
- Use tracking tools in order to identify exceptions, specifically look for permission violations and login exceptions identified as a job in application details. For SQL Server, you can use SQL Server Profiler. For Oracle, Azure, or AWS, you should use system views. Take into account that tracking has started only when you activate it. Therefore, you don’t have historical events to compare with.
- Review logs or auditing, if possible, in order to collect more data.
- Check which permissions are missing for the job to be completed and do proper testing before implementing chances.
Recommended action :
Ensure that the job’s owner has the correct privileges (GRANTs in Oracle, role permissions in SQL Server). The configuration can be general for all jobs running or specific for each job separately (best practice option for security). If the job needs access to an external path, make sure that the server where the instance is located has permission to access it remotely.
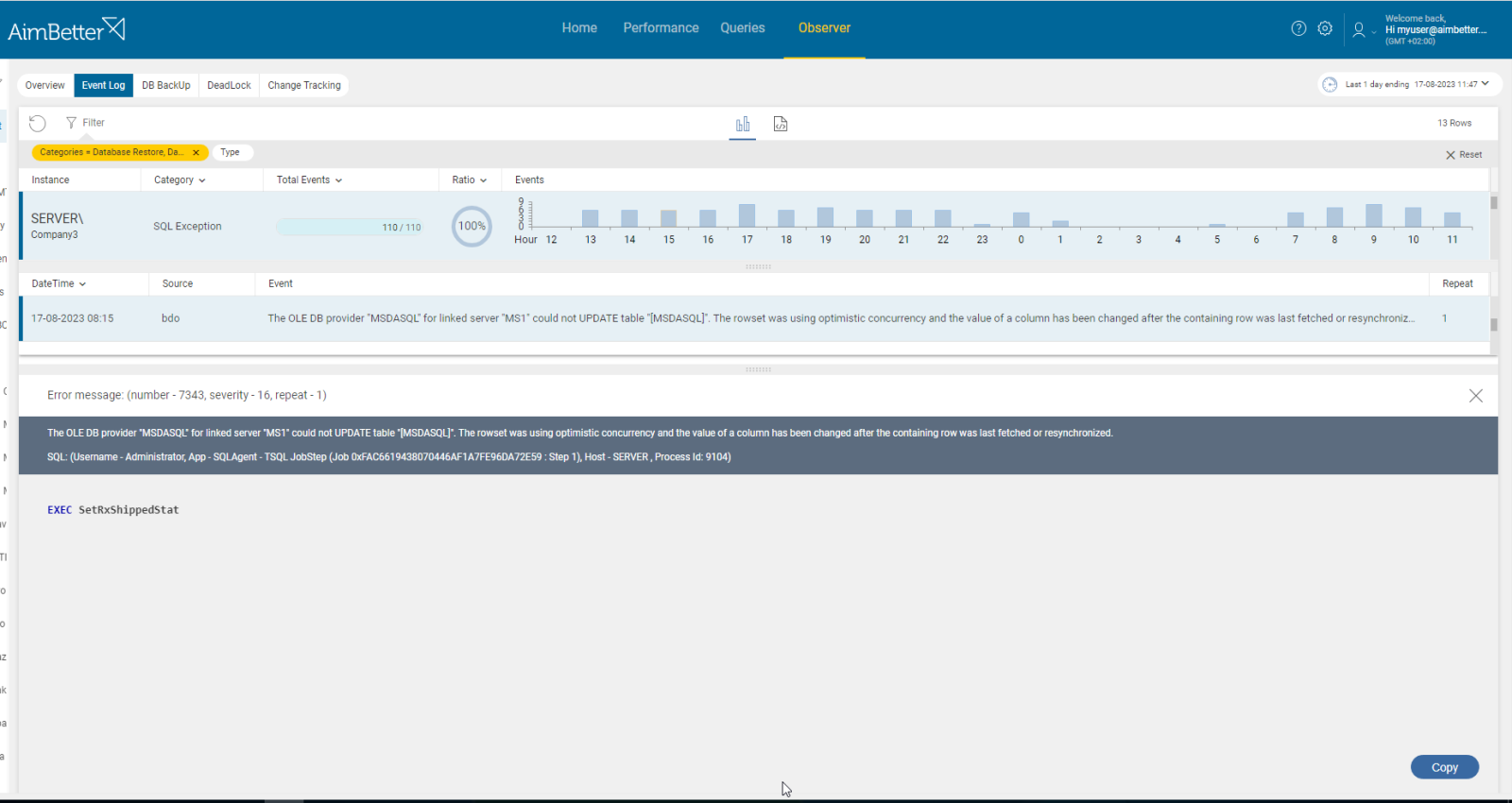
5- Connection to external resources. Priority: Medium
Unavailable external roots such as network shares, services, or linked servers (database links for Oracle) can conflict with the job’s successful execution and lead to failure. When the connection cannot be established and the job requires it, the process cannot continue.
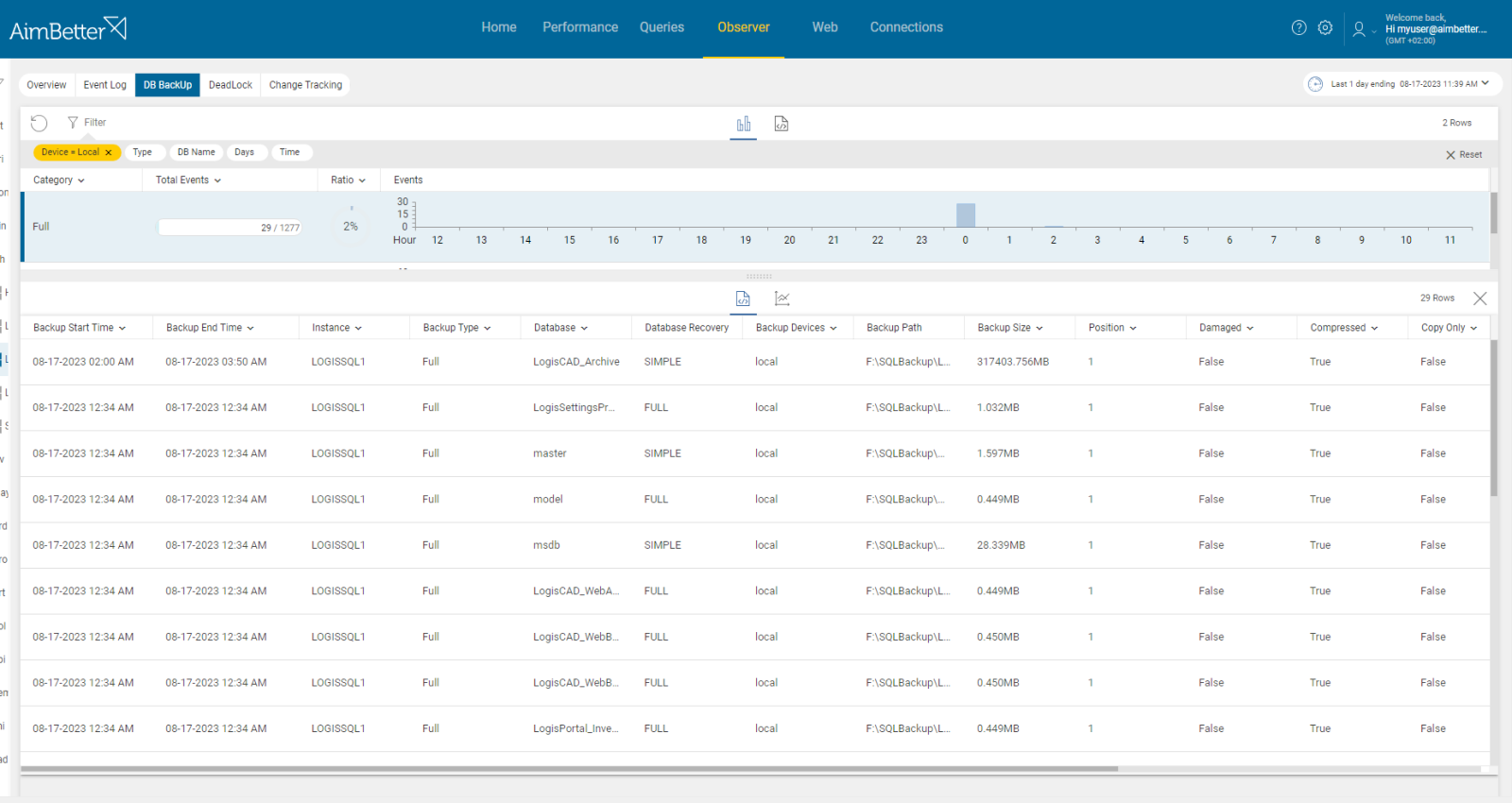
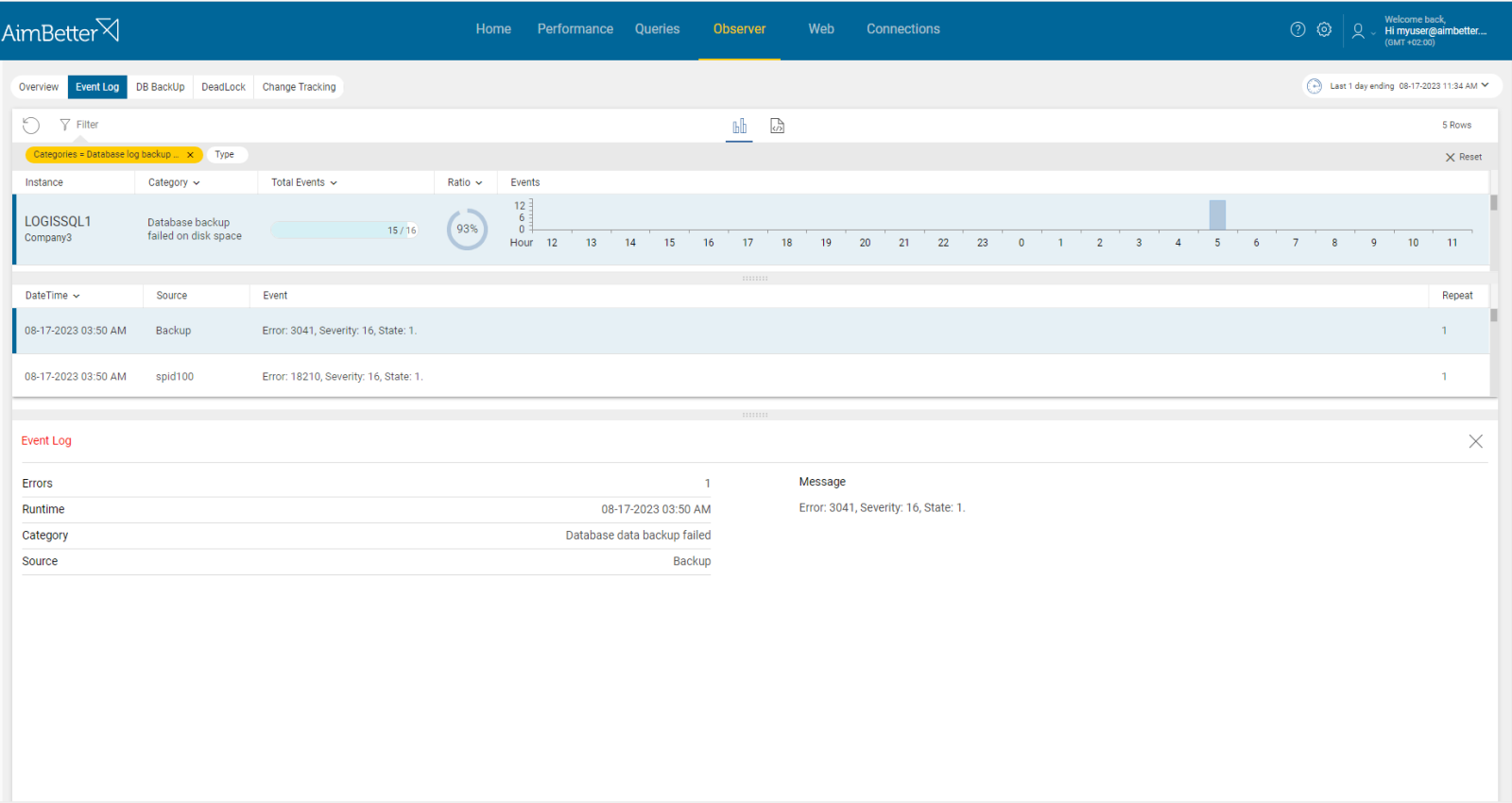
Specifically for backups, using network roots efficiently reduces local storage needs and is more secure. However, it may also lead to failure in the execution of the backup process when it faces connection issues.
Problem identification:
If the job’s error message is related to connection issues, track the relevant resources’ availability over time.
- Check for the job’s error message:
For SQL Server, you can use the Job Activity Monitor at the SSMS.
For Oracle, you can query the DBMS_SCHEDULER Jobs’ view.
For AWS or Azure, you can use logs. - Once you know the reason related to the connection issue, check what is the exact reason for it and if it’s the only reason for the failure. Test the connectivity to the resource in order to see if the problem is general or specific to the job.
- Check that all connection strings, authentications, and authorizations are correct.
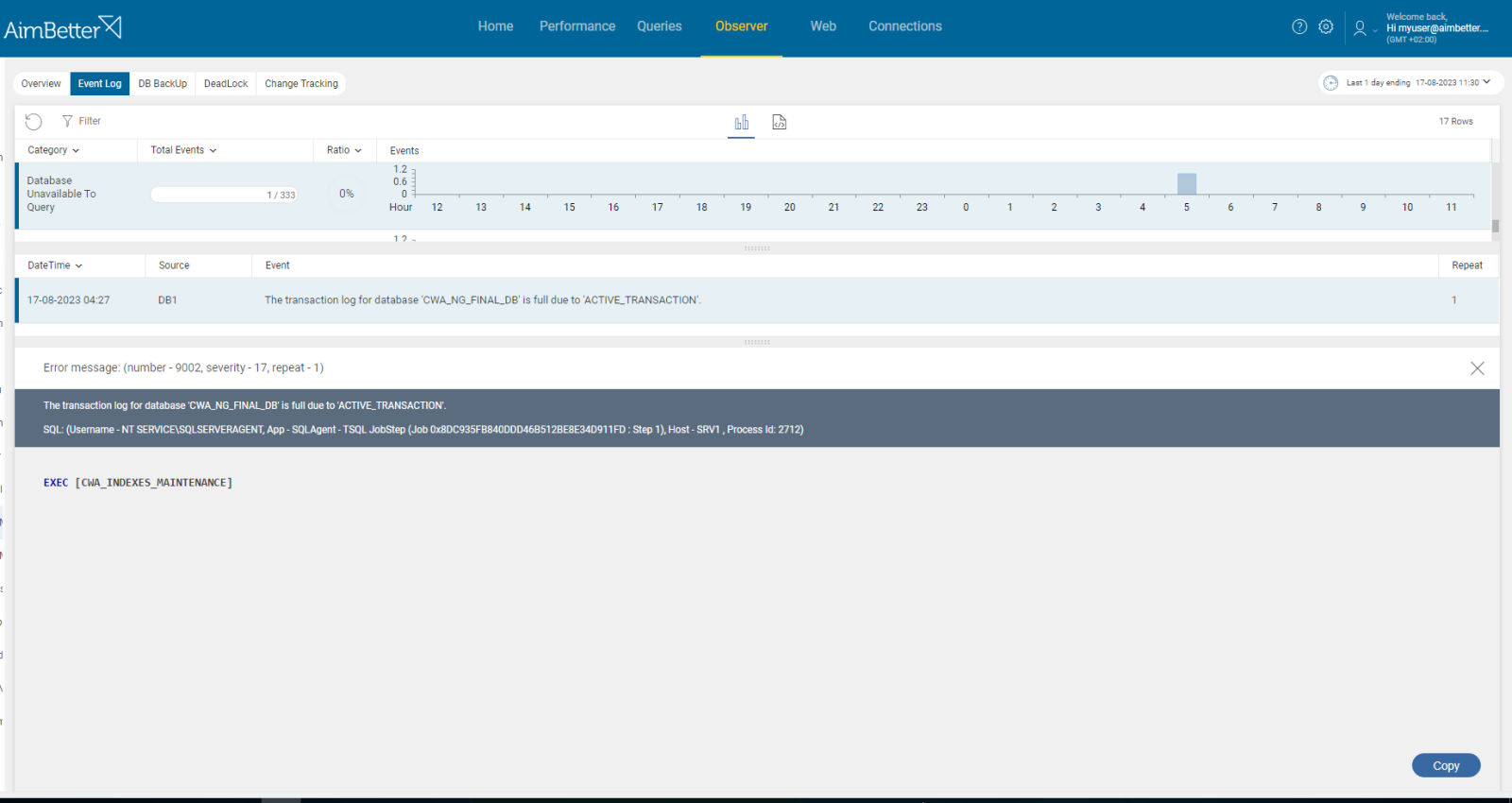
Recommended action :
Resolving connection issues leading to job failure can be done in several ways:
Check the connection string provided in the query code and if it has the correct authorization to the database.
Check network, firewall, and proxy settings.
Check for load balancer and database engine configuration.
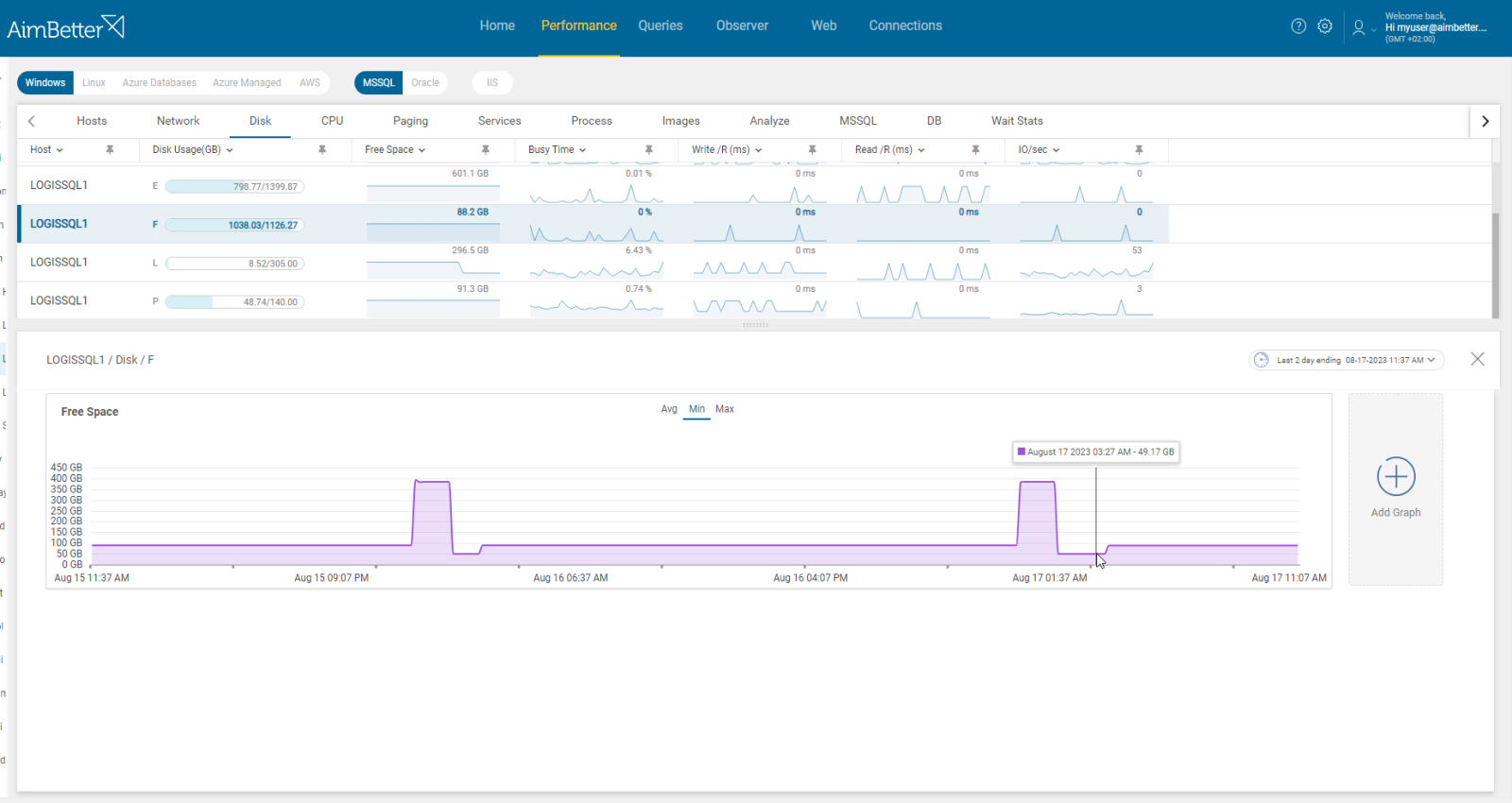
6- Resource overload or insufficient resources. Priority: High
A job may fail when it consumes too many resources. On the other hand, when the resources (Memory, CPU, or Disk space) are not enough for the job’s execution, it might also lead to failure.
Problem identification:
Investigate the job’s query during execution and check if it’s overloading OS resources or if the job error message alerts that there are not enough available resources to complete the execution successfully.
- Use tracking tools in order to identify exceptions, specifically look for resource exceptions identified as a job in application details. For SQL Server, you can use SQL Server Profiler. For Oracle, Azure, or AWS, you should use system views. Take into account that tracking has started only when you activate it. Therefore, you don’t have historical events to compare with.
- Review logs, if possible, in order to collect more data.
- Check if the reason for the jobs’ failure is because of an overload or missing resources.
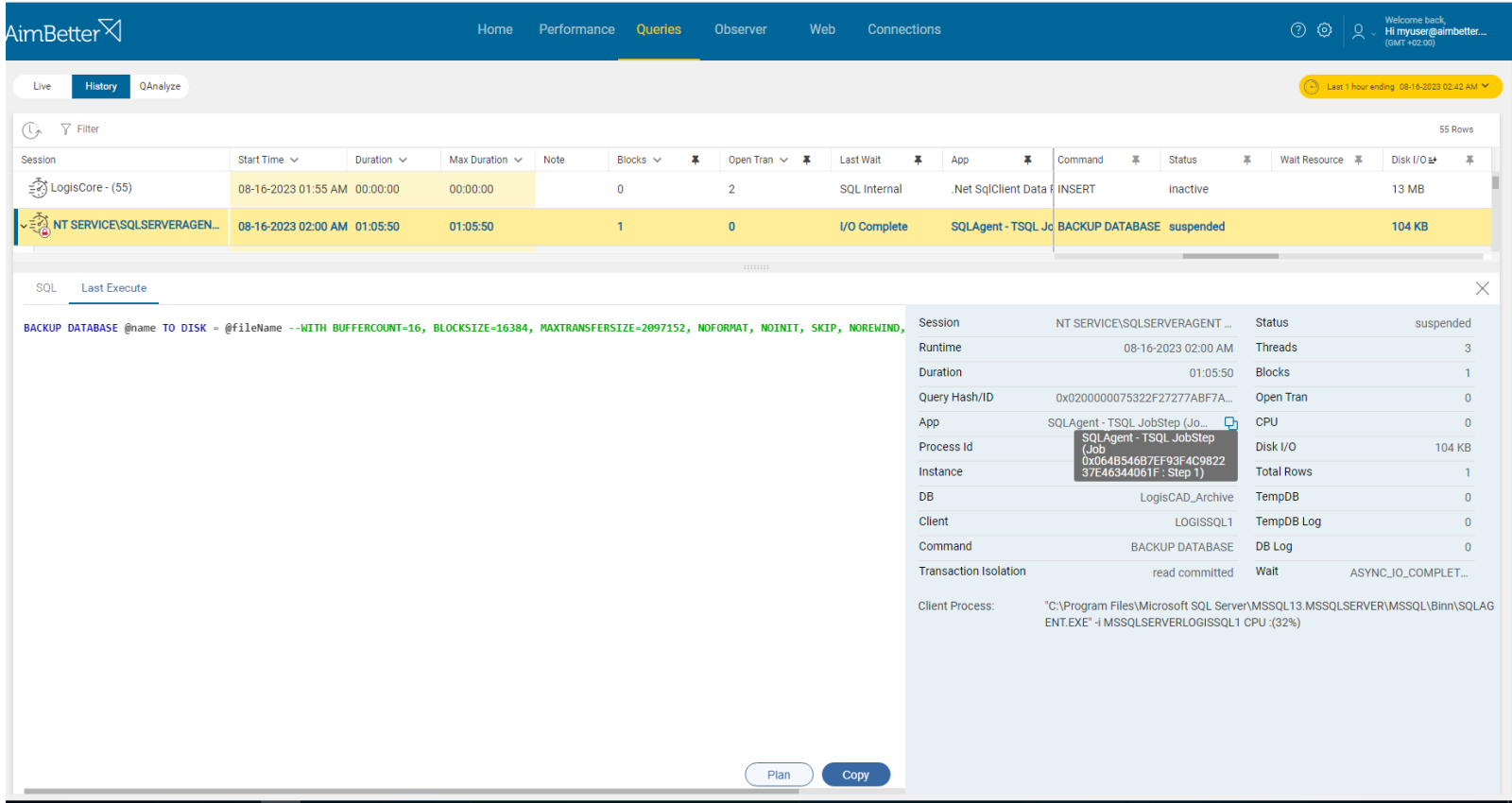
Recommended action :
If the job overloads OS resources, try to optimize and improve the query’s performance. In addition, if possible, upgrade resources according to needs- add more disk space, change paths to network paths, and add CPU Cores or RAM memory.
Take into account that this issue might hold queries from running and have side effects of blocking. It’s important to recognize the exact reason for the job’s failure.
7- Conflicting Operations: blocking or deadlocks. Priority: High
Blocking happens when another transaction has locked the table source and prevented this transaction from being committed since the table is already in use.
Deadlock happens when multiple processes or threads are waiting for resources held by one another at the same resource (instance). Oracle handles locking differently (row-level locking is the default). Deadlocks happen less frequently but still exist.
When other operations conflict with job processes, it can lead to job failures.
Problem identification:
Out of blocking or deadlock events, check which of them has jobs involved.
- Check details about the job execution time and query code.
- Use tracking tools, such as SQL Server Profiler, to identify blocking queries at the needed time range. This task might be complex since you have to make sure that the database and table in these queries are the same as the query that is running long. You should search for data related to session ID, wait duration, wait type, wait resource, and the code of the affected queries. In Oracle, V$SESSION and V$LOCK views help identify lock situations.
- Check the logs of queries and transactions. By analyzing the logs, you may be able to identify queries that are frequently blocking or causing deadlocks. Even knowing where to search might take time and be tiring. Other tools, like Distributed Lock Managers (DLMs), can help track the state of locks and identify potential deadlock situations.
- By comparing the blocking query to the queries of the affected jobs, you can determine if the blocking query is causing delays or long execution times for the affected queries. Make sure which of the affected queries is a job.
- Take into account that multiple layers of blocking or complex dependencies can exist. Therefore, you might aim for a wider insight by analyzing the transaction isolation levels, settings, and overall database workload.
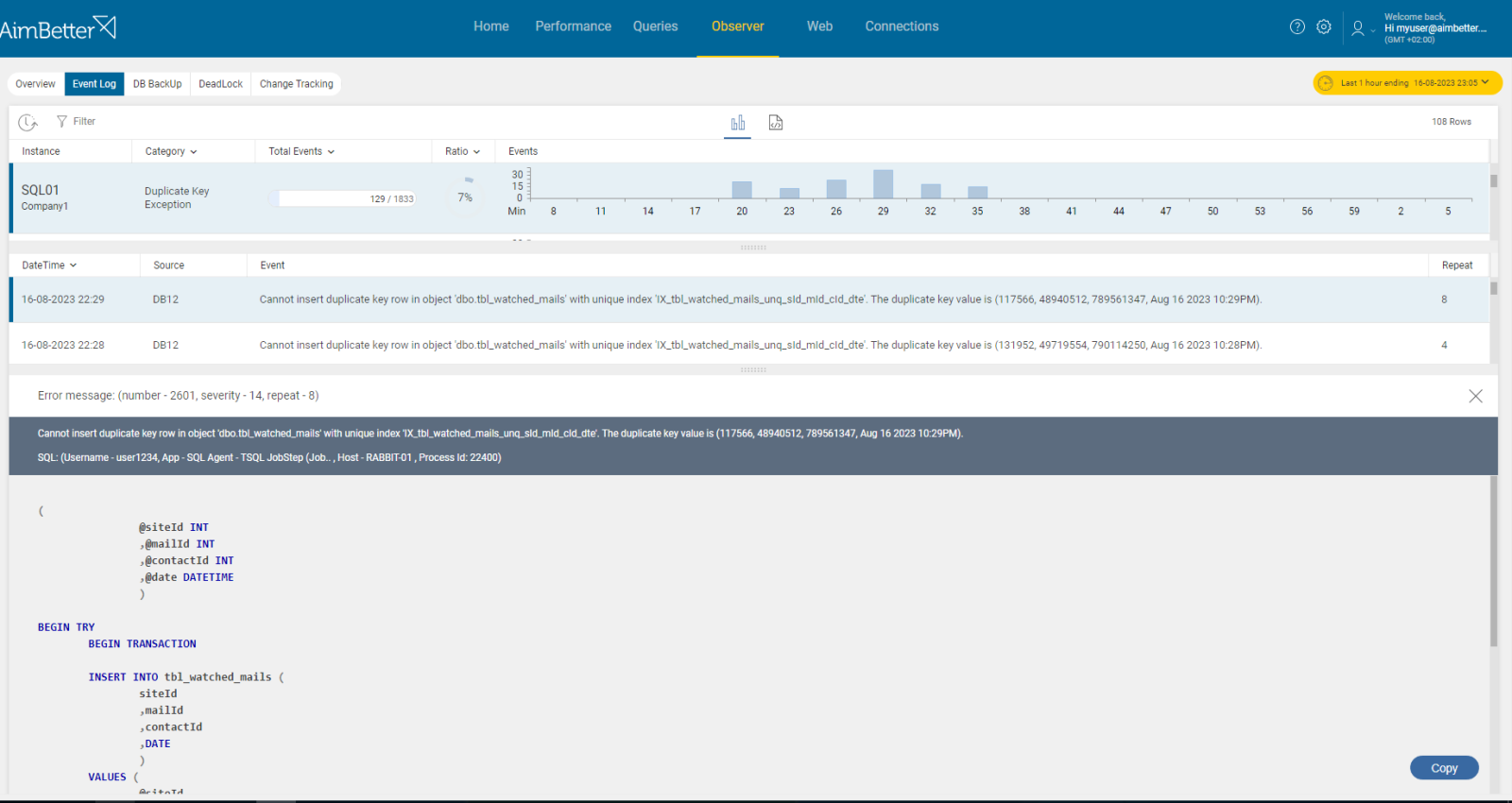
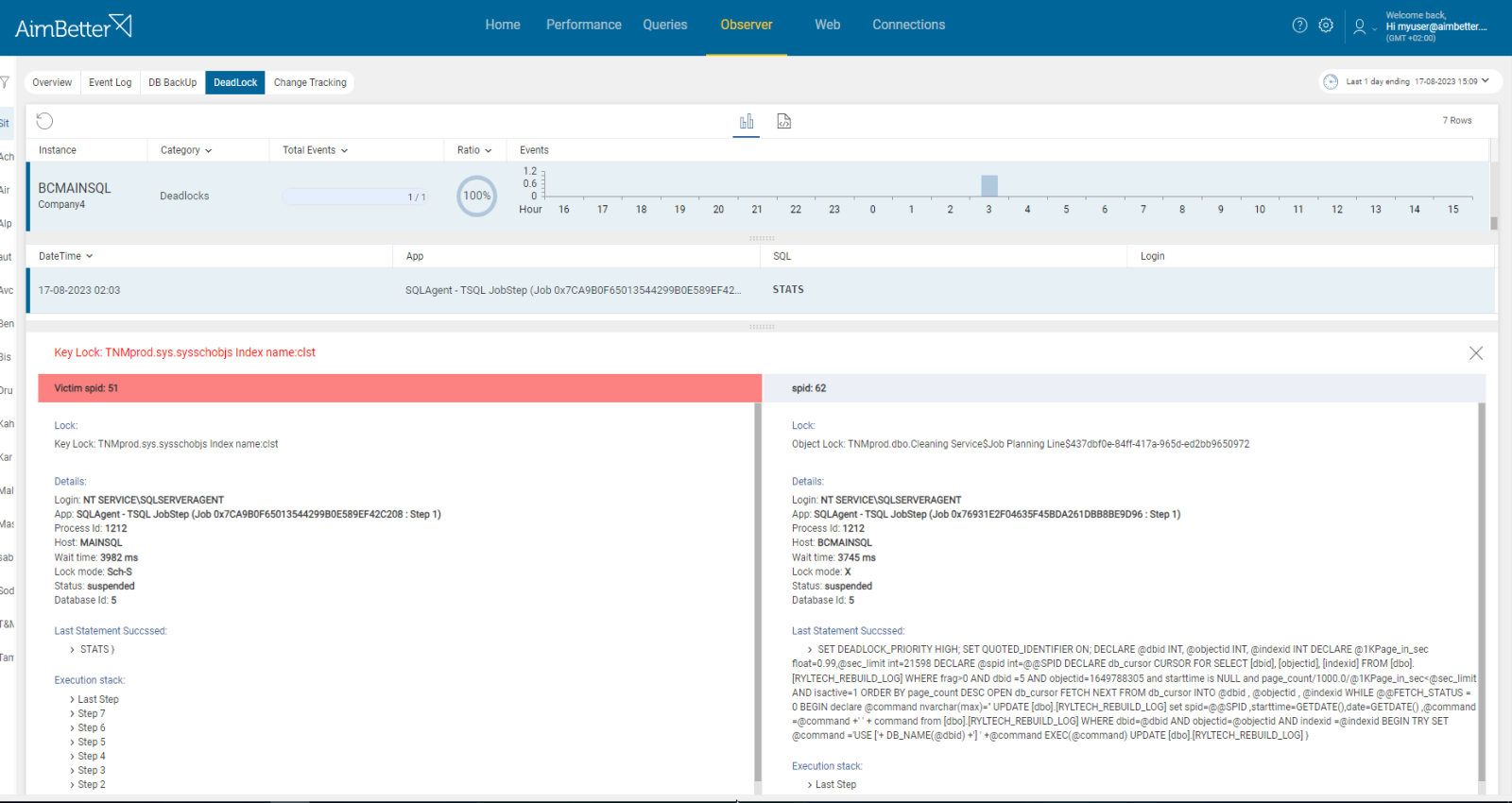
See in one panel all the layers related to blocking and deadlocks, including their details.
AimBetter provides you with the full aspect of deadlocks happening in the server, starting from session ID until lock key. It’s easy to find out which jobs are deadlock victims.
You can also search for a specific text, login, or application (job) and view historical events using the tool’s filters.
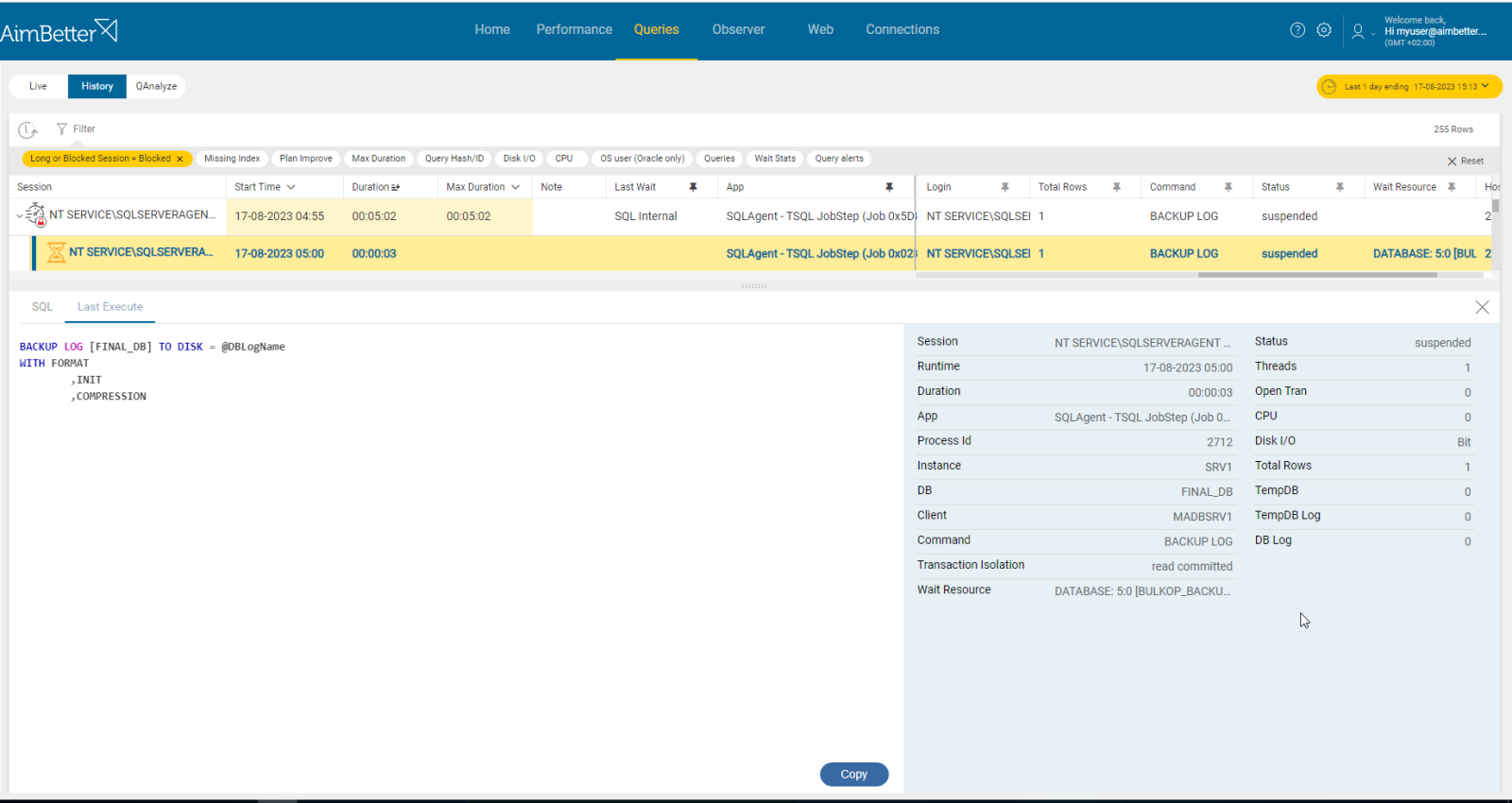
Recommended action :
To resolve blocking, you may need to adjust the query design and execution plan, optimize indexing, implement correct isolation levels, tune queries, and change settings if required.
Where possible, use “WITH (NOLOCK)” in reading transactions. Reprioritize processes according to needs.
To avoid deadlocks from happening, make sure resources are efficient (specifically CPU), and try to prevent conflicts with resource access by changing schedules of queries.
8- Server Environment Changes. Priority: Medium
This is a less common case, yet it’s essential to recognize it as the reason for a job’s failure when it happens.
Updates and configuration changes to Database instances or the host server might cause job execution to fail. Changes in security policies, including firewalls and proxies, can also cause job failure. Server restarts, shutdowns, or interruptions can disrupt job execution.
Ensure that character set and NLS parameters are compatible with job logic.
If the service account used to run the database service process is altered, the lack of necessary permissions can cause the job to fail.
Problem identification:
When resources, permissions, and exceptions have been checked, try to locate changes in the server’s environment.
- For changes done on the host level, check at the event viewer or in Windows panels. It might be hard to track since you need to know where and when to search for it. Check if server updates, configuration changes, or shutdowns were done close to the time that the job was executed and failed. You should also check for changes related to SQL services.
- Perform regular security reviews to ensure that the current configuration aligns with jobs’ activity needed requirements. Review firewall and proxy details.
- Review database logs and auditing in order to follow up recordings about logins and changes to database schema(or any database property). Focus on looking for unusual activity.
- Examine the resourcing test and check if resources are efficient.
- Out of all causes, you need to determine which is the cause of the job’s failure. Try to look for common properties to both the changes and the job.
Recommended action :
Make sure that the server’s planned tasks do not collide with scheduled jobs. Before implementing changes to the server or database, make sure that it won’t harm the performance of routine tasks such as jobs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}