RDB (Redis Database File) is a snapshot-based persistence mechanism in Redis. At specific intervals or based on configured triggers, Redis saves a snapshot of the in-memory dataset to disk (dump.rdb file). This allows data to survive restarts or crashes.
Impact
1. Data Loss Risk
-
If RDB fails, Redis may not have a valid backup of your data.
-
In the event of a crash or restart, recent in-memory changes could be lost permanently.
2. Hidden Failures Can Go Unnoticed
-
Redis continues to operate normally even if RDB save operations fail silently.
-
Without monitoring, you might assume backups are happening when they aren’t.
3. Disaster Recovery
-
RDB files are often the primary backup mechanism. If saving the file fails (due to disk space, permissions, corruption, etc.), recovery options are limited.
-
A failed RDB process could mean there’s no valid file to restore from in case of a catastrophic event.
4. Storage & File System Issues
-
RDB save failures often point to underlying infrastructure problems:
-
Disk full
-
Filesystem errors
-
Permission issues
-
Slow or failing disk I/O
Early detection of these problems can prevent broader system outages.
-
5. Compliance and Auditability
-
In regulated environments (e.g., finance, healthcare), backups are often required for compliance.
-
Missing RDB backups could put you at risk of violating data retention policies.
Possible causes for RDB failure
1. Insufficient Disk Space. Priority : High
Redis needs enough free disk space to write the dump.rdb file. If the disk is full or nearly full, the save process will fail.
Problem identification:
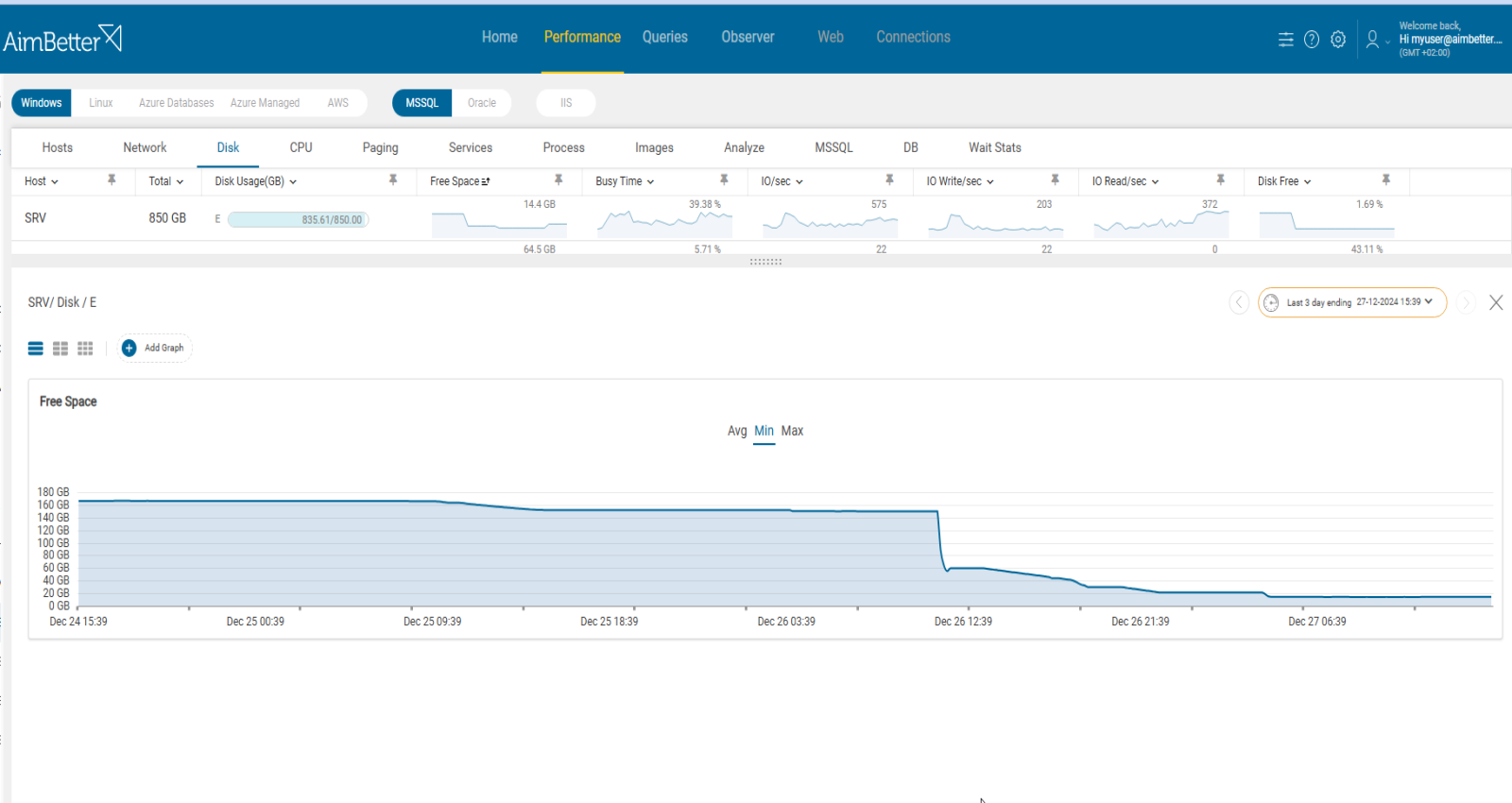
Identify if there is a disk space problem.
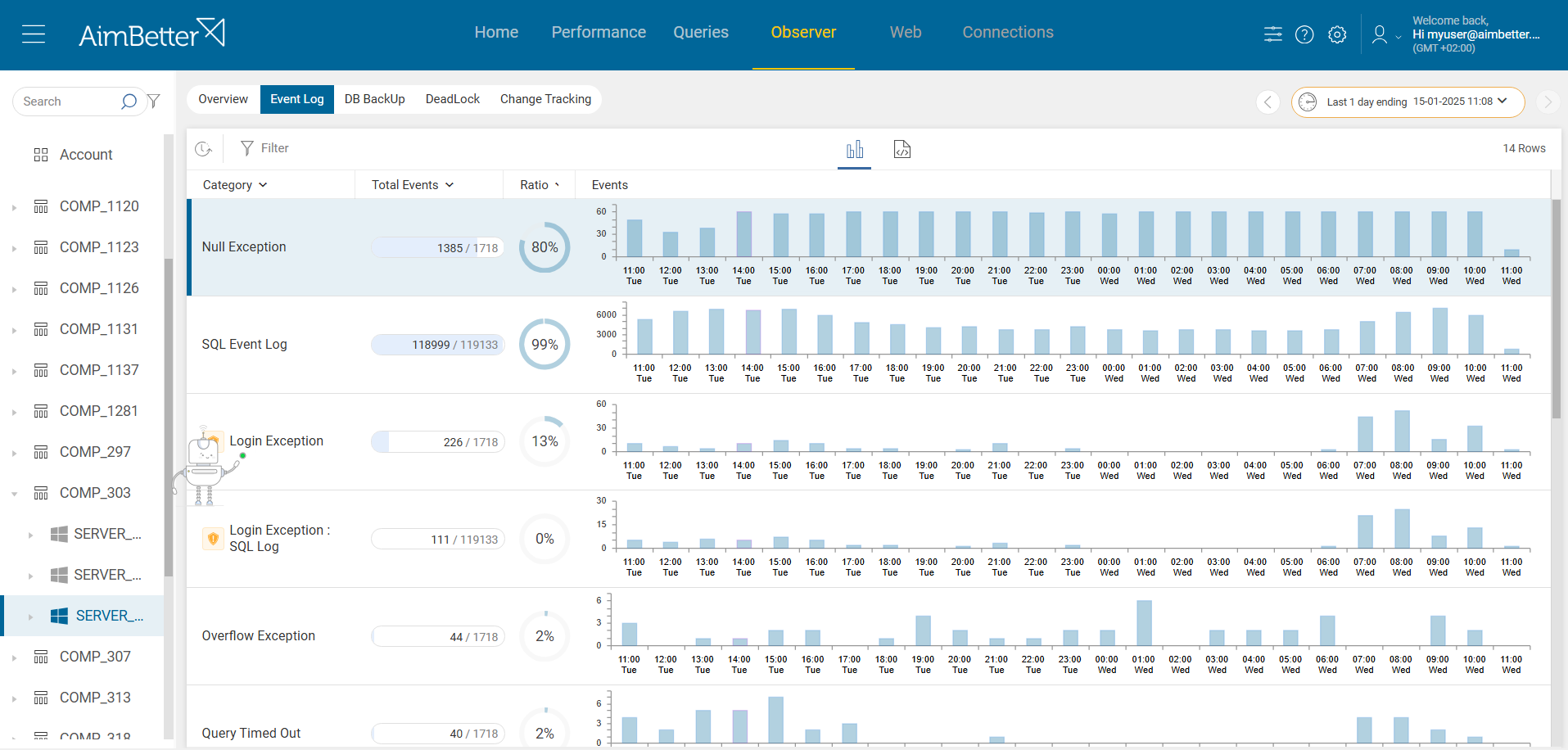
- Check Redis Logs: Look in the Redis log file (usually /var/log/redis/redis-server.log) for errors like: “Can’t save in background: No space left on device”/”Background saving terminated with an error”. This is the clearest indicator of a disk space problem.
- Run INFO Persistence in Redis. Use the Redis CLI: redis-cli INFO Persistence. Look for rdb_last_bgsave_status: fail.
This confirms that the last RDB save failed, although it doesn’t specify the reason. - Check Free Disk Space: Run a system-level check on the disk Redis is writing to. If the Avail column shows zero or is critically low, the RDB is likely to have failed due to disk space constraints.
- Check for Large or Growing Files: You may have large files consuming unnecessary space. Look for unusually large dump.rdb files, log files, AOF files (appendonly.aof) if enabled.
Recommended action :
Periodically delete or archive old Redis RDB or AOF files, logs (/var/log/redis/*.log), and temporary files in Redis directories.
Use a Redis monitoring tool like AimBetter to alert on rdb_last_bgsave_status: fail and lack of disk space.
2.Filesystem or Disk I/O Errors. Priority: Medium
Slow, failing, or corrupted disks can interrupt the write process. Examples: filesystem errors, disk I/O timeouts, hardware failure
Problem identification:
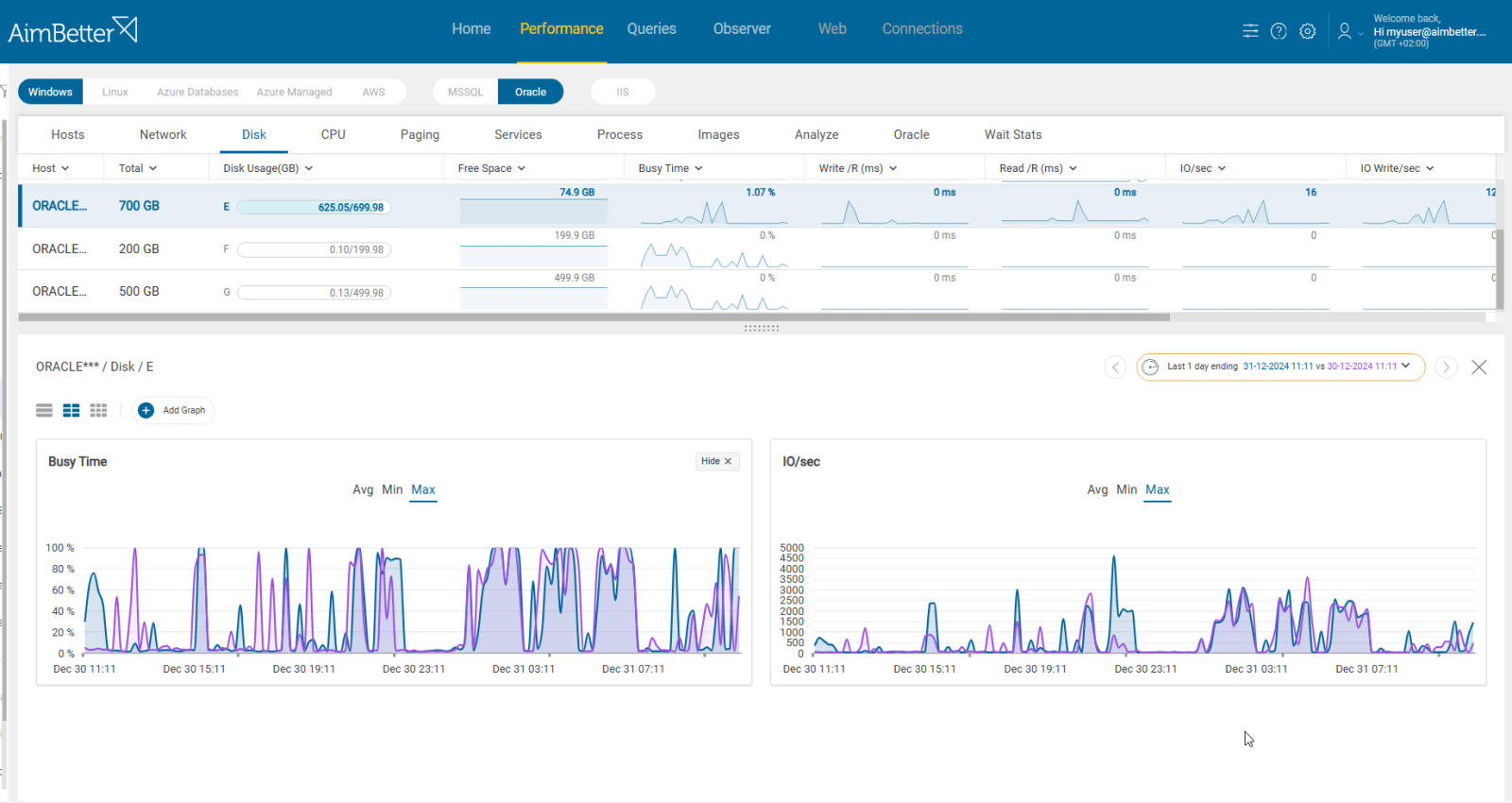
Identifying filesystem or disk I/O errors is critical when troubleshooting Redis RDB failures or general system instability. These errors often manifest subtly at first but can lead to severe data loss or performance degradation if left unchecked.
- Check System Logs: The system logs are the first place to look. Common error messages: I/O error, Buffer I/O error on device sda1, EXT4-fs error, Remounting filesystem read-only. These are strong indicators of disk or filesystem problems.
- Check Mount Status of Filesystems: If Redis’s data directory is suddenly mounted as read-only, writes will silently fail. Look for ro (read-only). If it’s read-only, it likely remounted due to a filesystem error.
- Run Filesystem Checks (Offline or Carefully Online) to check and fix errors.
- Monitor Disk I/O Latency. High latency could mean failing disks or contention. On Linux, use iostat.
- Redis Log Clues. In Redis logs, look for “Background saving terminated with an error”/”Can’t save in background: I/O error”. This confirms Redis couldn’t write to disk, often due to filesystem or hardware issues.
Recommended action :
- Use Reliable Hardware (SSD over HDD). Prefer enterprise-grade SSDs for Redis workloads. Avoid cheap or low-end flash storage, especially for write-intensive workloads. Use RAID (e.g. RAID 10) for performance + redundancy.
- Enable Filesystem Journaling and Use a Stable FS. Use modern, journaled filesystems.
- Mount with safe options: defaults,noatime,nodiratime. Consider fsck on reboot to auto-fix errors.
- Monitor Disk Health and I/O Load Continuously with tools like AimBetter.
3- CPU, Memory or I/O Contention. Priority: High
If the system is under heavy load, Redis might timeout or fail to complete the save process in a reasonable time.
Problem identification:
Identifying high CPU, memory, or I/O contention is crucial for diagnosing Redis performance bottlenecks, especially during RDB saves or periods of heavy traffic. Contention occurs when multiple processes compete for the same resources, resulting in delays or failures.
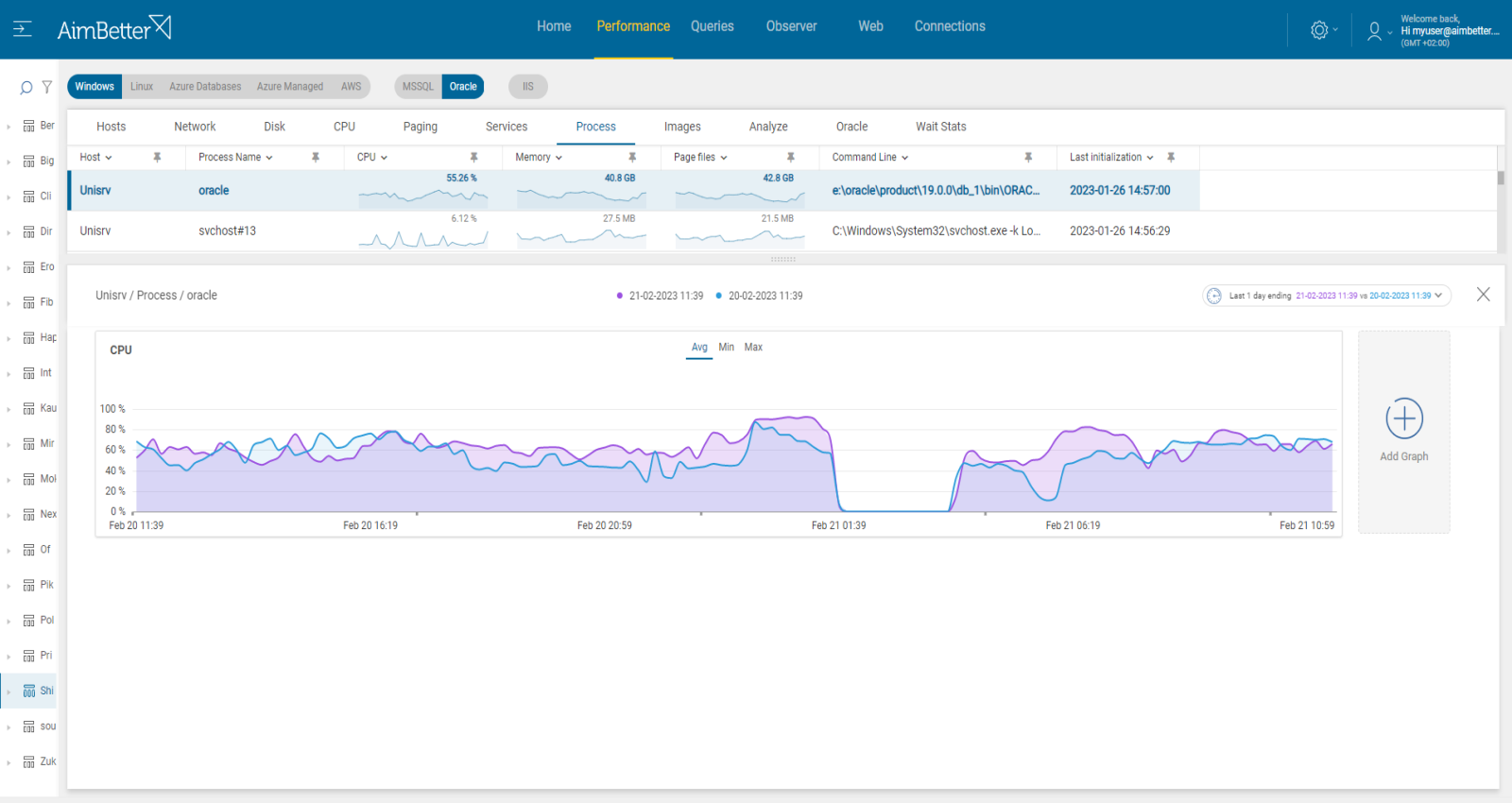
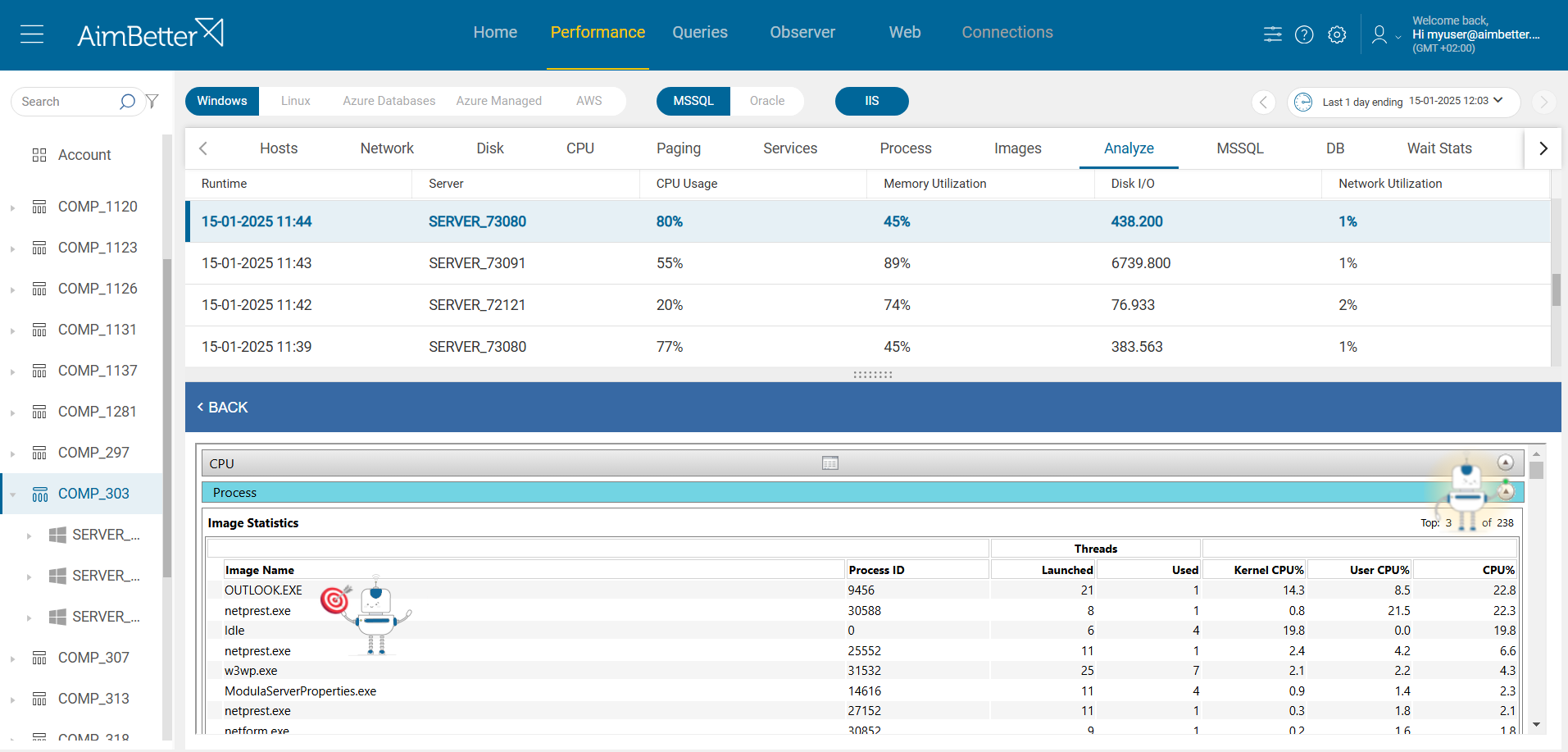
- Monitor Hardware Resource Overload on Windows and Linux. On Windows, use Task Manager to check for hardware resource overload. On Linux, use system tools such as top, htop, or glances to view CPU, memory, and disk usage in real time.
- Use OS and Network Monitoring Tools. On Windows, use Performance Monitor (perfmon) to identify which processes consume the most resources. On Linux, use tools like pidstat or ps to analyze process-level resource usage, iostat and vmstat for disk and memory statistics, iftop, nethogs, or vnstat to monitor network activity and bandwidth usage per application.
If there is an issue with any hardware resource, AimBetter will immediately alert you about it.
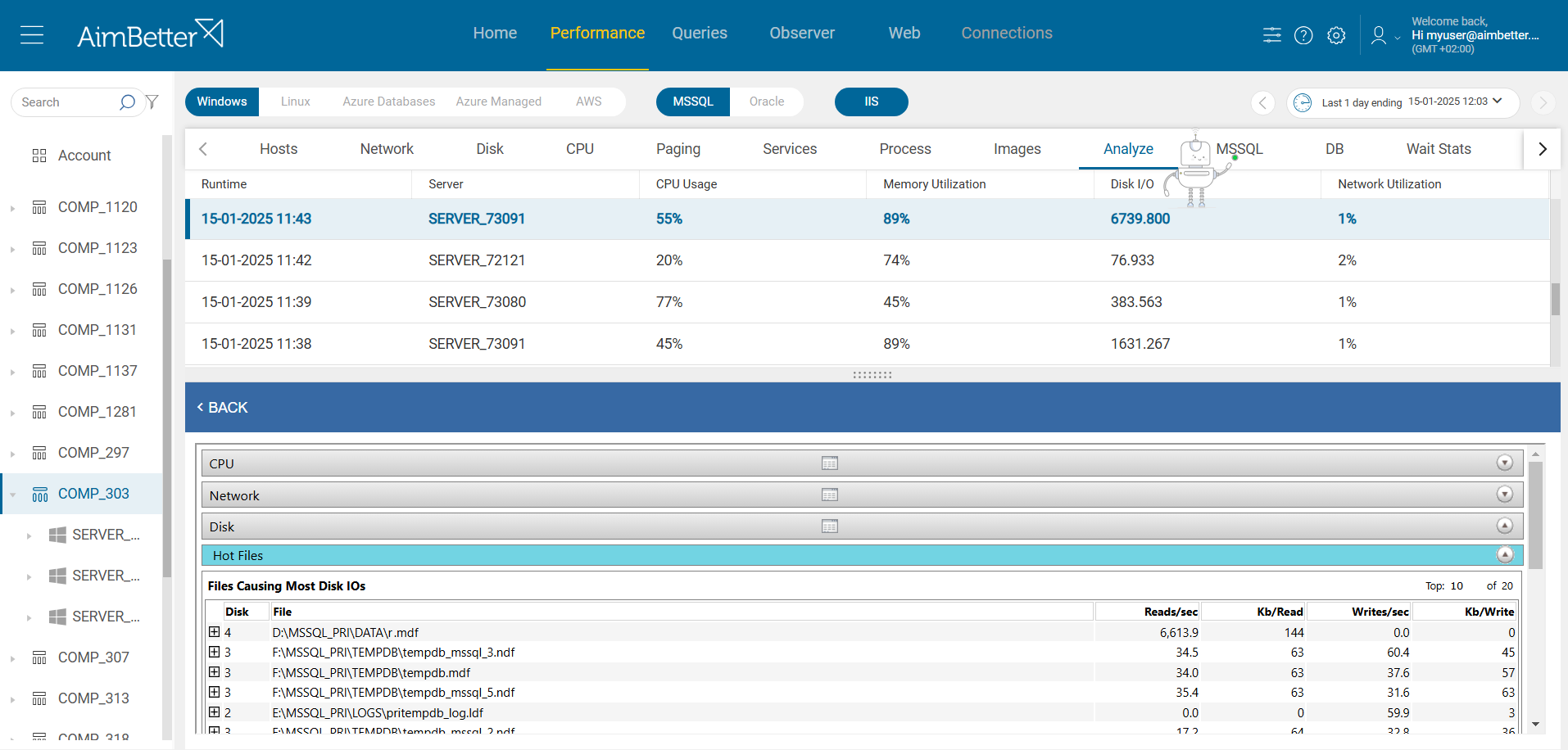
Comparing time frames is easy when working with a single panel, which allows you to view multiple metrics simultaneously.
In AimBetter’s Analyze tab, you can check the processes responsible for the high CPU, memory or Disk I/O.
Recommended action :
To avoid high resource contention (CPU, memory, disk I/O, and network), especially in environments running Redis, SQL Server, Oracle, or other critical systems, you need a combination of proactive capacity planning, workload optimization, and effective monitoring.











{kind=link}
{kind=link}
{kind=link}