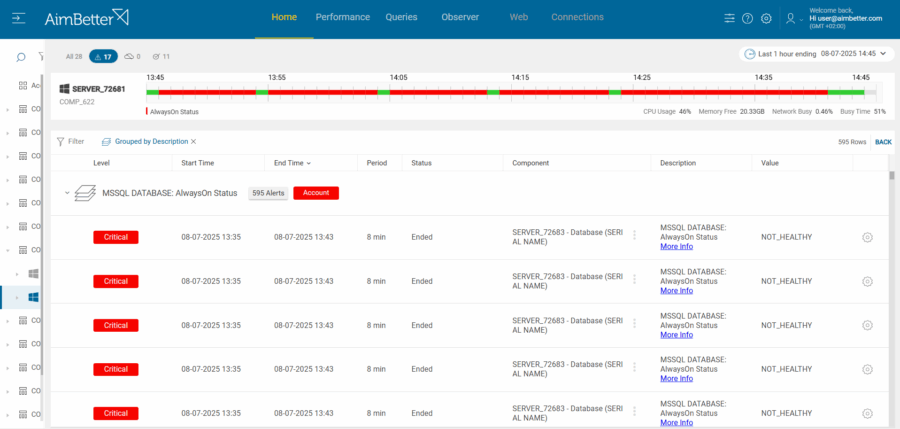
This case is a powerful reminder of how AimBetter not only detects problems but also enables immediate action and provides a view of what happened at every point in time, even when everything appears to be fine on the surface!
One of our enterprise customers, operating a critical production environment with stringent availability requirements, relies on a SQL Server Always On Availability Groups setup. Their configuration includes one primary production node and three secondary replicas—one configured for automatic failover and two designated for business intelligence (BI) workloads such as reporting and analytics. This architecture is designed to offload read-intensive operations from the primary system and ensure high availability in case of failure.
Recently, AimBetter’s proactive monitoring capabilities proved vital when our alert system triggered a warning that the Always On availability group was not healthy.
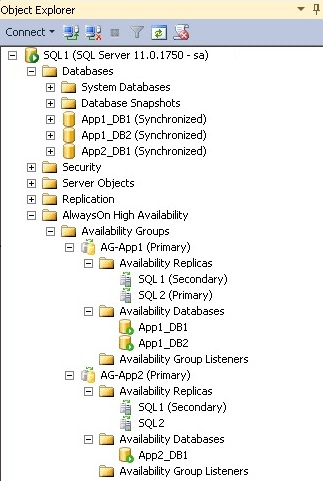
When the DBA connected and opened the SQL Server Management Studio to investigate, everything appeared to be functioning normally—no error messages, performance issues, or failover symptoms were visible from the primary node’s perspective.
The Always On Dashboard in SSMS provides a high-level overview of all configured Availability Groups. At first glance, everything may appear healthy—all nodes show as synchronized, and no issues are immediately apparent. This summary view, while useful, can be misleading if a deeper problem is occurring at the replica or database level.
However, thanks to AimBetter’s Availability Groups alert and its full visibility across all nodes in the Always On topology, it became clear that replication to the secondary nodes had silently stopped.
To uncover such issues, the DBA must drill down into each individual Availability Group and then further into each replica node.
The BI systems were no longer receiving updated data, and the designated failover node was not synchronized. Without AimBetter’s insight, this issue would have gone completely unnoticed, possibly leading to outdated analytics, reporting inaccuracies, and a failed failover in the event of an outage.
Adding to the root cause identification (which started with the alert itself), AimBetter’s intuitive drill-down interface allowed the DBA team to quickly navigate from the high-level alert into detailed Always On status metrics, supported by historical graphs. With just a few clicks, they could visually confirm the exact moment when synchronization was lost and compare behavior across nodes. This eliminated guesswork and dramatically reduced the time to resolution.
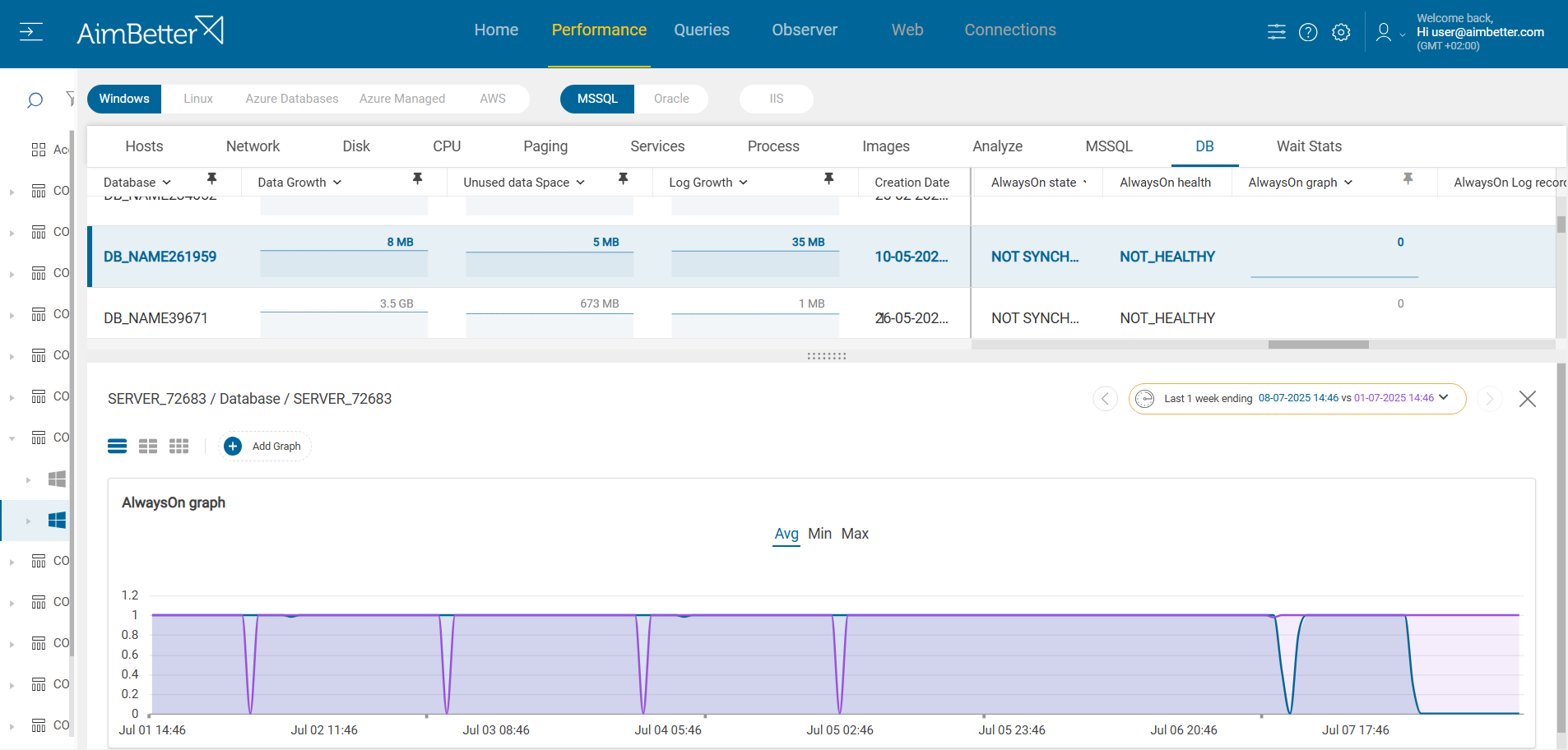
AimBetter not only detects what’s wrong but also enables deep, actionable analysis through a clear and historical view of key SQL Server metrics—like the Always On status graph—ensuring database teams are always a step ahead of potential risks.






