Recovering from an Allways On cluster crash in SQL
April 2018
Introduction
Recently one of our customers was presented with a sudden warning of abnormal behavior on their cluster of database servers. Clusters are a powerful tool for sustaining server availability and performance but are acknowledged as adding a significant level of complication to the operating environment.
This case illustrates how by having the right tools in place to firstly pick-up quickly that something needed attention and then to have enough information immediately accessible, the database administrators were able to spend a minimum amount of time investigating but were rather be able to go straight to the root cause and fix it.
This study is especially relevant to any organization that is contemplating extending into a clustered environment but has been deterred by the potential complications. AimBetter removes the danger and adds all the necessary levels of control and supervision to make clustering a positive and rewarding facility.
The “secret weapon” in this case was AimBetter’s monitoring and alert mechanism, which raised the necessary flags, and pointed to the proper remedy, in just a few minutes.
Background information
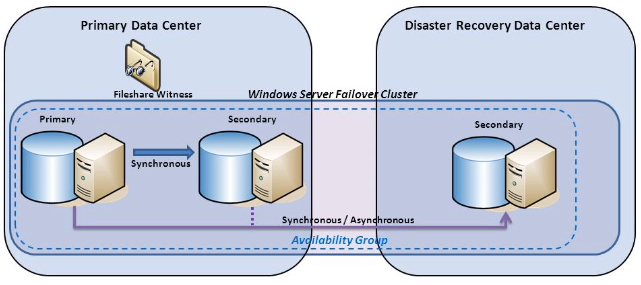
The company has a critical dependence on database performance and adopts a “zero-tolerance” approach to response latency, downtime or outages. For this reason, an extended cluster of servers has been implemented, including one instance “in the cloud” on Azure. The primary database is shared across this cluster.
Summary of this event
We give a complete description of all the details in the rest of this study on following pages, but for simple step-by-step analysis, the following gives you a clear picture of how this problem was solved:
- At 08:35, database on AZURE clustered server cannot connect with PRIMARY SQL instance
- At 08:38 there is a WINDOWS CLUSTER crash because of a problem accessing a network folder that is required for proper operation of the CLUSTER
- The WINDOWS CLUSTER falls.
- The databases on inhouse servers entered ‘NOT SYNCHRONIZING’ state and then entered ‘NOT_HEALTHY’ status.
- AimBetter system alert raised on console and customer alerted via email.
- At the same time, the customer’s administrator reports 2 minutes of inability to perform transactions.
- AimBetter expert administration team member tracks the source of the problem via drill-down through Performance metrics.
- The problem of failed communications with Azure is identified.
- Communications were restored, WINDOWS CLUSTER was back up and the system resumed syncing.
- Data integrity and normal functionality restored at 08:40.
- The whole process, from start to completion, took less than 5 minutes!!!
Important to note is that all of this happens in real-time on a single console, with AimBetter support and customer’s administration able to see and respond to the same console information, without need for over-the-shoulder or VPN access into the customer’s site.
The symptoms
The company received an alert from the AimBetter monitoring system that service had changed status from ‘Running’ to ‘Stopped’. Such notifications are triggered automatically by AimBetter’s service to alert on-site administrators via email with details of the behavior requiring attention.
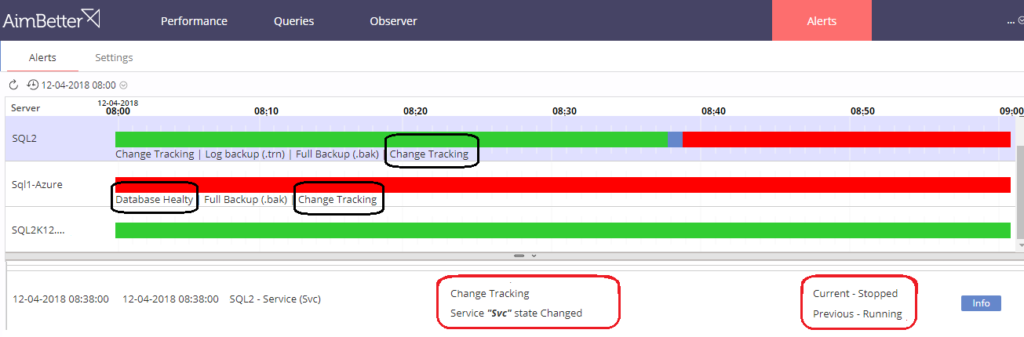
The investigation
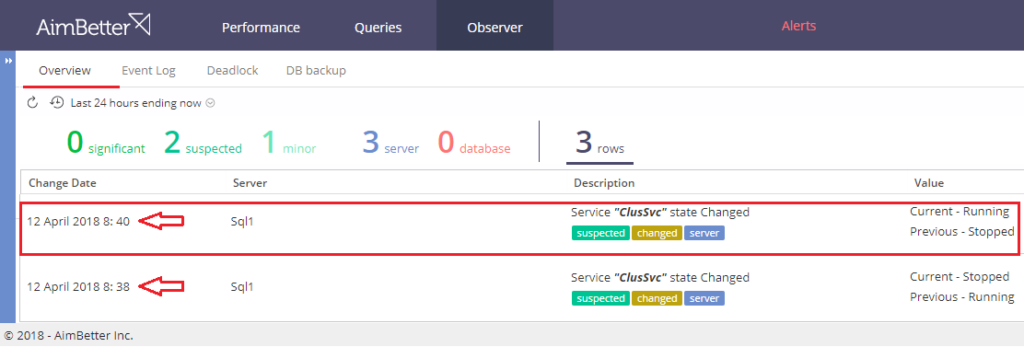
AimBetter console provides one-click access to changes and exceptions via the Observer panel.
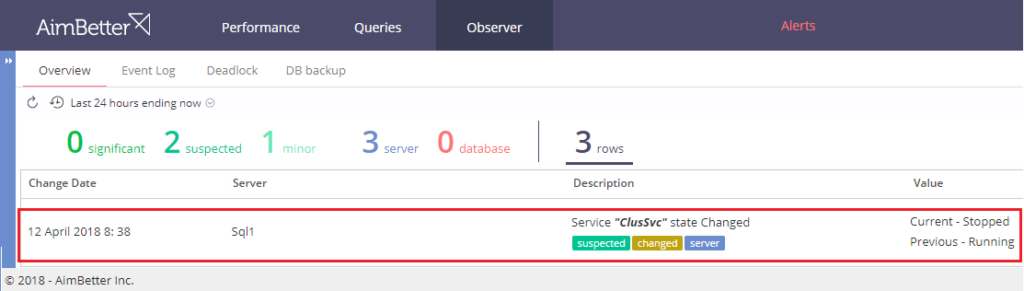
The immediate point of interest on this screen is that the problem relates to the cluster, from the “CluSrv state changed from Running to Stopped” message. From this, the administrator can switch immediately inside the Observer panel into the Event Log, displaying all database activity inside the relevant timeframe:
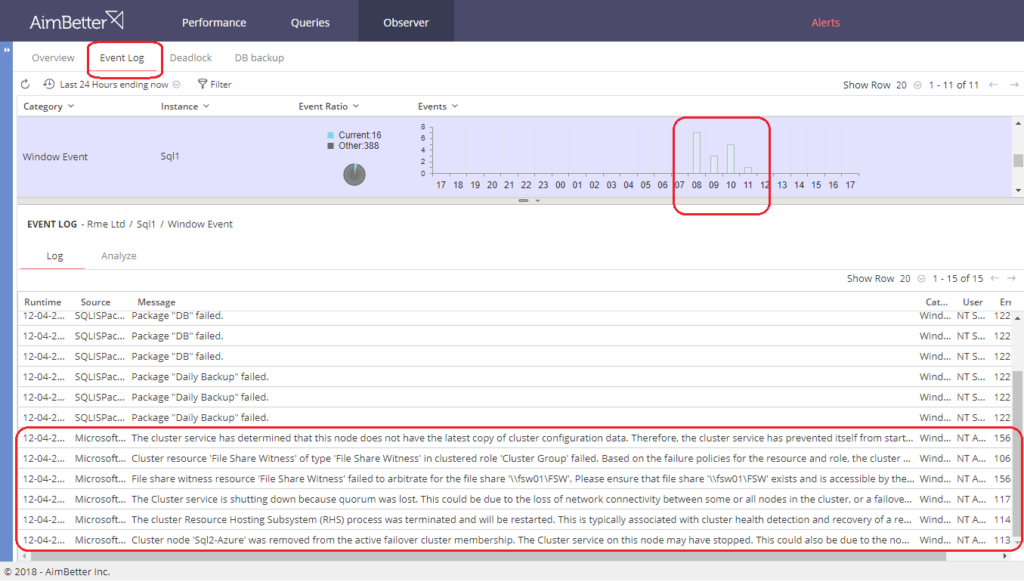
The clear message from these Microsoft OS warnings points to a failure in communications between the cloud-based clustered instance on Azure and the central servers. (Full text of the messages is appended in Note 2 at the bottom of this report).
Finally, with the information gleaned from the previous screens (server, database instance, a manifestation of the alert) we could bring up the relevant picture which reports on the “Always On” status of the cluster.
The Diagnosis
Putting these together, we were able to advise the customer’s database managers there had been a break in communication between the Azure cloud instance and the rest of the cluster. This resulted in the operating system forcing the cluster into “NOT HEALTHY” mode with the resultant crash.
With this information, the customer’s administrator knew exactly how the crash had been triggered, and took the steps to restore the communication path between the local and cloud-based instances. As soon as this was done, the cluster was reinstated and data synchronization restored. The following snapshot shows that the whole process took just two minutes!
The cure
While the customer recognizes the benefits of having clustering, it is clear that it needs to take steps to prevent catastrophic failures such as this coming from the added level of complication that clustering introduces. They turned to our Expert Support team for help, and we were able to suggest a number of solutions to overcome this situation. The main purpose of any such solution is to be proactive and identify such problems as this before they actually manifest in such a serious outage. Obviously, it is not possible to guarantee 100% availability of communications over an external network, so the solution needs to concentrate on isolating the cluster instance as soon as communication failure is detected, and therefore leave the primary cluster operating normally.
In the case of this customer, the Quorum consists of 3 servers plus one file share. (For a detailed explanation of how clusters are managed, see our note below). When communications are not available to the cloud, two votes are lost in the CLUSTER Quorum, resulting in loss of quorum. If a dynamic quorum scheme is adopted, this will not result in the server losing health.
We could offer a number of possible solutions that depend on the customer’s priorities and budgetary considerations.
If the choice is to retain clustering (usually chosen where high-availability is the primary requirement so that they retain the infrastructure to monitor and coordinate failure detection and automatic failover) or to minimize the possible cost of reconfiguration, there are several options. In the first place, we had to rule-out two which were not applicable in this case:
- to switch away from a split cluster, to a configuration fully based on Azure or similar cloud configuration. (This would allow for use of Microsoft’s GEO-Disaster Recovery feature.) In the case of this customer, this option was not considered viable, largely due to the added problems the remote infrastructure adds in terms of security and response times.
- Owing into the limitations of SQL MIRRORING (mirrored databases cannot exist alongside clustered; only one database can be in a mirror; on failover, the database can only be accessed using a different server name) staying with clustering (using ALLWAYSON technology) appear to be to the main solution
This then leads to our next possibilities:
- SQL Server Log shipping allows for transaction log backups to be automatically sent from a primary database (on a primary server instance) to one or more secondary databases (on separate secondary server instances). The transaction log backups are applied to each of the secondary databases individually. The benefits of this are:
– provides a disaster-recovery solution
– supports limited read-only access to secondary databases
- It is possible to tune the clustering parameters that determine actions when a connection between nodes is interrupted: for frequency (defines the frequency at which cluster heartbeats are sent between nodes) and threshold (the number of heartbeats which are missed before the cluster takes recovery action). These parameters in tandem can be used to hold the faulty node in suspension without losing the quorum.
- More generally, it is recognized that clusters are more stable if they have an odd number of nodes. In the case of this customer, there are 4 nodes, and the loss of a single location (Azure server and file witness on the same physical connection) resulted in the cluster crash. A solution here is to add one more node (either a replica of the database or another file witness) on a separate connection.
Alternately, if the additional investment is considered viable, they now have the choice introduced in SQL 2017 for Read-scale availability groups without the cluster. In earlier SQL Server versions, all availability groups required a cluster. Now, it is possible to use read-only routing or directly connect to readable secondary replicas. It is no longer necessary to depend on integration with any clustering technology in order to obtain the benefits of the ALLWAYSON features.
Our customer has taken these recommendations on-board and begun compatibility testing to make the correct choice.
AimBetter does it better.
Firstly, abnormal patterns are highlighted in real-time, with notification to our Expert Support Team and the user’s administrators immediately the problem is registered.
Secondly, the analysis of the event happens in real-time. There is no need to reconstruct the circumstances – everything that was happening is stored inside our database and can be recalled, analyzed and displayed in a single operation without the need to directly access the whole cluster itself.
Finally, AimBetter is a complete service. Proper health maintenance for a data environment has many similarities to personal health. The saying “prevention is better than cure” applies equally in both cases, and any good practitioner will prefer to identify problems before they manifest and take appropriate action. AimBetter is the best diagnostic tool for the database environment because it does both of those things – it minimizes problems by keeping your database healthy, and whenever something goes wrong, it is immediately useful in finding the cause, and pointing you in the right direction for correction and cure.
Technical note 1 – about Clustering Health.
Health of a cluster is defined via a voting mechanism. The total cluster is represented as a QUORUM, consisting of a number of host nodes and two possible witness types (file-disk or share-file).
Each node has a VOTE and the witness also does (but witnesses can be counted differently). In a cluster, nodes can be in one of 3 states: Online, Offline or Paused.
The Quorum Scheme determines how votes are counted:
- Node majority – Each node in the cluster has a vote
- Node and disk majority – Each node in the cluster has a vote as does a shared disk witness
- Node and file share majority – Each node in the cluster has a vote as does a file share witness
Most importantly, the cluster must have the majority of “online” votes to be viewed as operational. The counting is affected by the overall scheme. In case of a static scheme, the total number of nodes is constant, so in cases where nodes are shut off, they are counted as “offline” and therefore as a negative vote. In dynamic quorum schemes, nodes that are shut down are removed from the count altogether.
Technical note 2 – Microsoft responses
- ‘SQL1-AZURE’ with id [xxx-xxx-xxx-xxx-xxxxx]. Either networking or a firewall issue exists or the availability replica has transitioned to the resolving role.
Cluster node ‘Sql2-Azure’ was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
\nCluster node ‘Sql1-Azure’ was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
- File share witness resource ‘File Share Witness’ failed to arbitrate for the file share ‘\\xxx\FSW’. Please ensure that file share ‘\\xxx\FSW’ exists and is accessible by the cluster.






